
Domain-Specific Knowledge Graph Builder (Patents/Legal Case Law Focus)
An agentic system that ingests, connects, and surfaces interconnected concepts from structured, domain-specific literature (e.g., patent claims, legal case law) into a unified, actionable knowledge graph for specialized professionals.
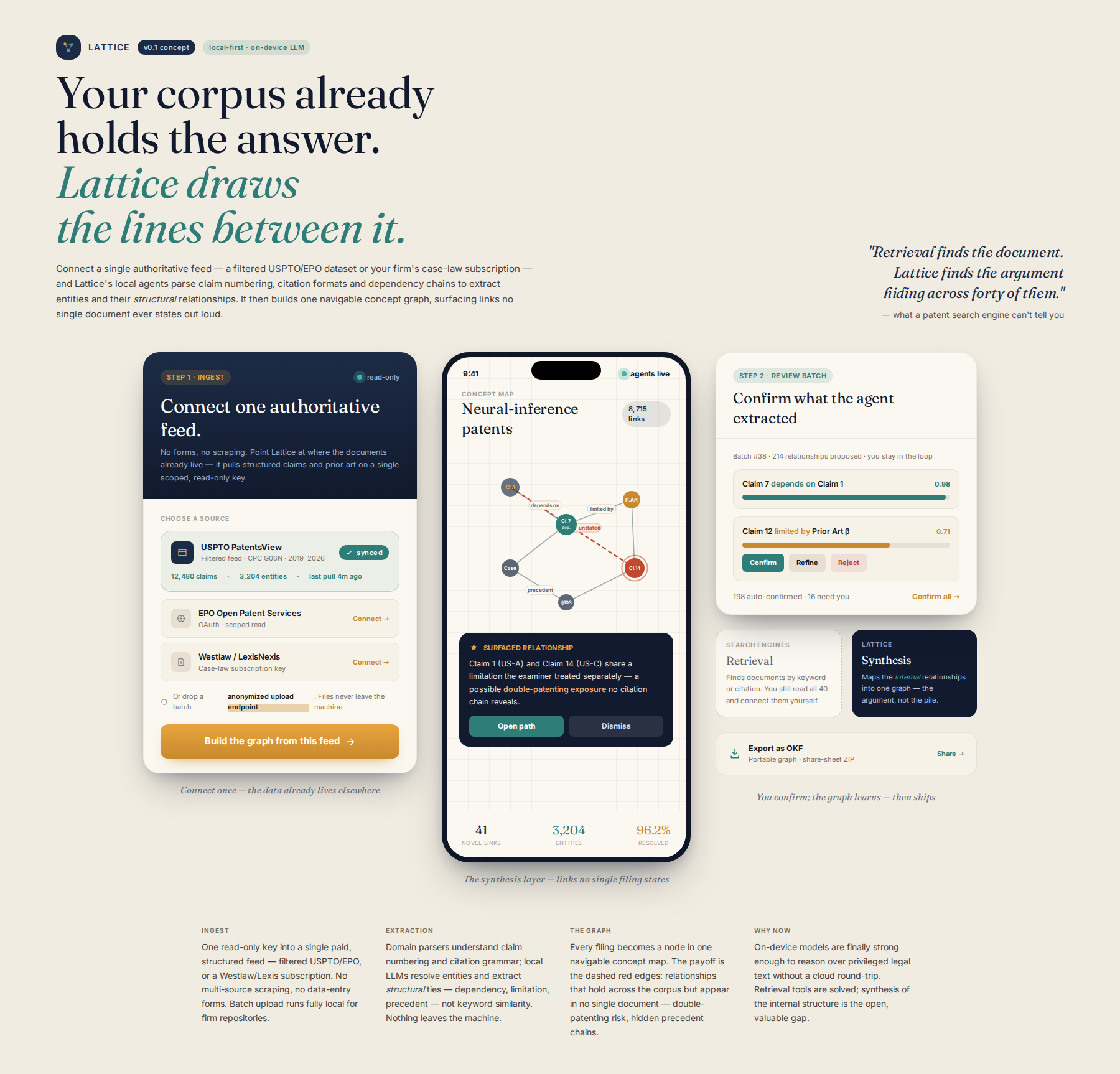
Process flow
Who it's for
Patent attorneys, IP lawyers, domain-specific R&D teams, and researchers needing structured relationship mapping.
Why they need it
Professionals in highly regulated or technical fields struggle to synthesize knowledge across vast, structured documents (like patent filings or case law) to identify subtle conceptual links, prior art, or legal precedent that simple keyword searching misses. The pain is the difficulty in mapping relationships between standardized concepts across a large corpus.
What it is
A proactive, local-first knowledge agent that ingests structured documents (e.g., USPTO/EPO data feeds, case law text) to extract core entities, identify explicit relationships (e.g., 'Claim X depends on Prior Art Y'), and build a dynamic, interconnected knowledge graph for review and hypothesis generation.
How it works
The user connects to or uploads structured datasets/documents. The system uses specialized parsers designed for domain structure (e.g., understanding patent claim numbering or legal citation formats). The core logic runs on local LLMs to perform entity resolution, relationship extraction (focusing on structural relationships like 'dependency,' 'limitation,' or 'precedent'), and graph construction, visualized through a local GUI.
Differentiation
Existing tools (e.g., specialized patent search engines, legal databases) are excellent for retrieval (finding documents based on keywords or citations). We focus on semantic synthesis of the internal relationships within the corpus. We fill the GAP of transforming a collection of discrete, structured documents into a single, navigable, interconnected 'concept map' that surfaces novel relationships not explicitly stated in any single document.
Implementation sketch
- Prototype the initial ingestion pipeline using a stable, structured data source subset (e.g., a small set of USPTO patent claims documents).
- Integrate the memoryengine framework to process structured text chunks into triples, specifically training the relationship extractor on domain-specific predicates (e.g., 'is_dependent_on', 'limits_scope_of').
- Build a minimal local graph visualization front-end allowing users to query relationship paths (e.g., 'Show all concepts that limit the scope of Claim 1 in relation to Prior Art X').
First step: Download 10-20 sample patent claims (or legal case summaries) and write a small script to parse the document structure (e.g., identifying 'Claim X' and its associated text block) to test the initial ingestion parser.
Remaining risks
- Domain Expertise Dependency (The 'Last Mile' Problem) — The system's value is entirely dependent on the user's ability to correctly define and train the relationship extraction predicates (e.g., knowing the difference between 'dependency' in patent law vs. 'precedent' in common law). If the initial training/prompting for these specialized predicates is insufficient, the graph will be semantically accurate but practically useless to the expert user.
- Data Source Volatility and Access Barriers — While patent/legal data is more structured than comments, accessing the full necessary corpus (e.g., all historical USPTO filings) requires navigating complex, often paywalled, or rate-limited government/legal APIs. Failure to secure reliable, high-volume data streams will stall the product beyond the initial prototype stage.
- Graph Overload and Cognitive Load — The very success of the system—connecting too many disparate concepts—can overwhelm the expert user. If the graph surfaces 100 related concepts, the user needs a highly sophisticated, AI-guided filtering/summarization layer (e.g., 'Show me the 3 most novel connections between Claim 1 and the last 5 years of prior art') rather than just a raw visualization.
Watch for: When expert users begin treating the system as a 'second search engine' rather than a 'synthesis tool.' If they only use it to validate what they already know (i.e., it just returns known connections), the core value proposition of surfacing novel relationships is failing. Kill criterion: If the initial ingestion pipeline cannot reliably parse and extract the core structured elements (e.g., identifying a specific 'claim number' and its associated text block) from 10 consecutive, different sample documents, the technical foundation is too brittle for the stated high-stakes domain.
Sources the council used
Real-world evidence that grounded this idea — judge it for yourself.