
Autonomous Hypothesis-Driven Research Engine (AHRE)
A local, resource-constrained system that autonomously manages and executes research workflows by iteratively testing falsifiable hypotheses derived from a user-provided set of claims.
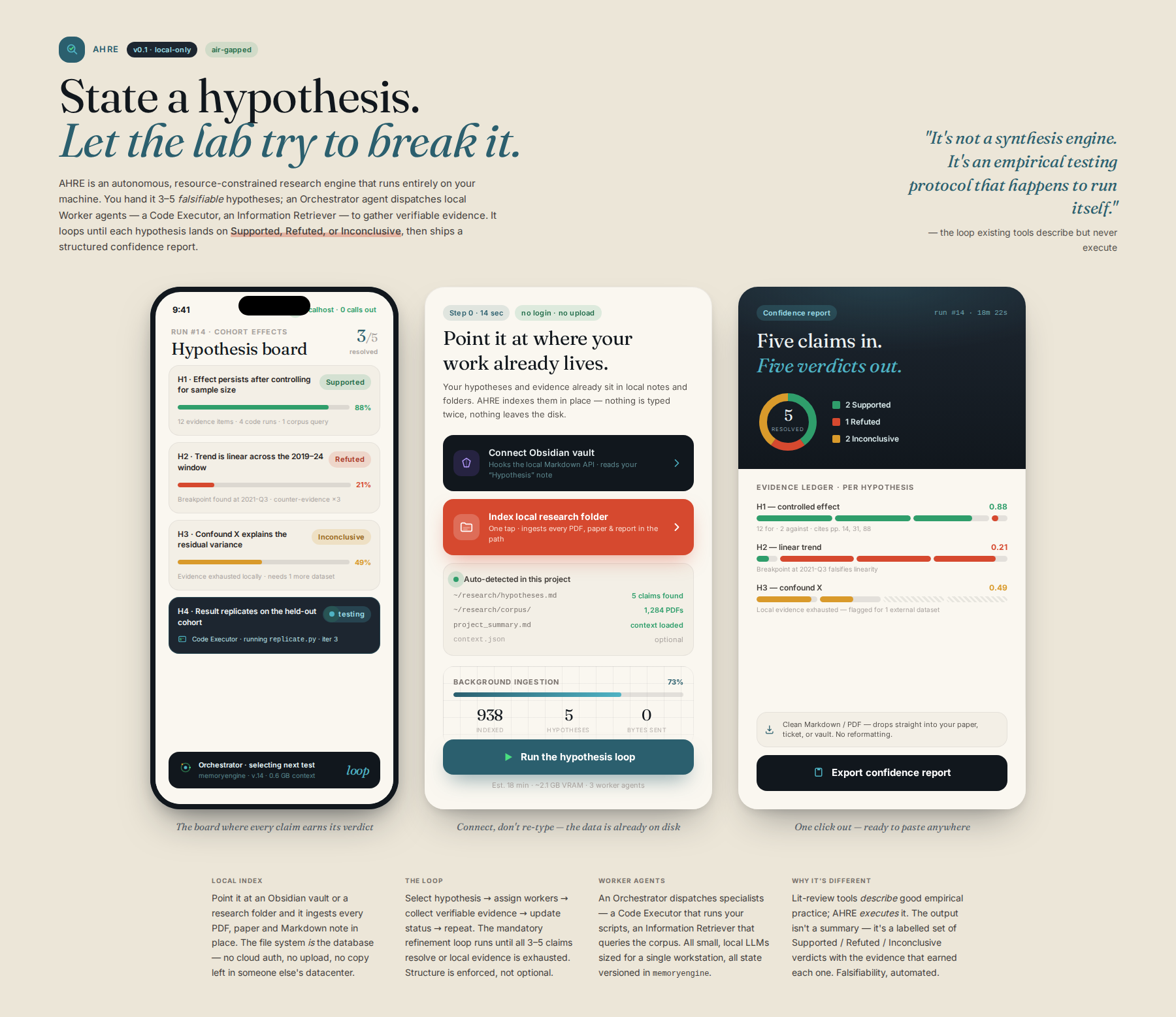
Process flow
Who it's for
Independent academic researchers, advanced hobbyists, and small R&D teams operating with sensitive or air-gapped data.
Why they need it
Traditional research workflows are slow and require manual orchestration. The current bottleneck is the difficulty in structuring abstract questions into a series of verifiable, testable claims. AHRE automates the 'Hypothesis-Testing Pipeline' itself, turning vague objectives into rigorous, traceable validation protocols.
What it is
A software framework built around specialized, local LLM agents designed to manage a structured, iterative loop. It accepts a set of user-provided, falsifiable hypotheses and executes the necessary research steps to gather evidence to validate or invalidate each hypothesis, concluding with a structured confidence report.
How it works
The process begins with the user inputting 3-5 specific, falsifiable hypotheses. The 'Orchestrator Agent' manages a structured, iterative loop: 1. Select Hypothesis $
ightarrow$ 2. Assign specialized 'Worker Agents' (e.g., 'Code Executor Agent', 'Information Retrieval Agent') to test the hypothesis $
ightarrow$ 3. Collect verifiable evidence $
ightarrow$ 4. Update the hypothesis's status (Supported/Refuted/Inconclusive) $
ightarrow$ 5. Loop until all hypotheses are resolved or evidence is exhausted. All state is managed via a persistent, versioned context memory (memoryengine) operating locally.
Differentiation
This differs from general agentic systems by enforcing a strict, mandatory Hypothesis Refinement Loop. It is not a general synthesis engine; its output structure must be a set of validated/refuted hypotheses, treating the research process as an empirical testing protocol. It explicitly addresses the gap where existing tools (e.g., specialized literature review platforms) guide users through best practices but do not automate the execution of the structured, iterative validation loop itself.
Implementation sketch
- Integrate the 'memoryengine' context layer to track hypothesis state (Support/Refute/Inconclusive) for auditability.
- Develop a dedicated 'Hypothesis Runner Module' that accepts N hypotheses and manages the structured execution flow.
- Refine Worker Agents to ensure evidence collection is explicitly tied to the hypothesis being tested, preventing context bleed.
- Implement a 'Convergence Monitor' within the Orchestrator to manage the loop termination condition (e.g., all hypotheses resolved, or X failed attempts).
First step: Build a minimal mock Orchestrator loop using Python's asyncio framework. The loop should accept a hardcoded list of 3 mock hypotheses and cycle through them, calling placeholder functions for 'Test_H1()', 'Test_H2()', etc., to prove the state-updating mechanism works before integrating any LLM calls.
Remaining risks
- The 'Convergence Monitor' logic is complex and brittle. If the evidence collection process results in ambiguous or contradictory data for a hypothesis, the monitor might fail to correctly classify the state (e.g., deadlock, insufficient data, or conflicting evidence), leading to an unresolvable loop or premature termination. — Implement a tiered escalation protocol. If the monitor detects ambiguity (e.g., >X inconclusive results in a row, or evidence contradicting the current status), it must automatically pause the loop and generate a structured 'Human Review Prompt' detailing the conflicting evidence and asking the user to manually resolve the state before proceeding.
- The system assumes the quality of the input hypotheses. If the user provides hypotheses that are mutually exclusive, logically flawed, or based on outdated premises, the entire engine will execute flawlessly but produce a fundamentally incorrect or useless conclusion, leading to 'automation bias' where the user trusts the process over the results. — Introduce a mandatory 'Hypothesis Pre-Check' module. Before starting the loop, this module must run a basic consistency check (e.g., checking for logical contradictions between the N hypotheses) and force the user to acknowledge the system's assumption that the initial set is logically sound and non-contradictory.
- The 'Worker Agents' are specialized, but their failure modes are not fully defined. A failure in one worker (e.g., the Code Executor Agent hitting a sandbox timeout, or the IR Agent failing to parse a specific data format) must not crash the entire state machine, but must instead generate a structured, actionable error state that the Orchestrator can gracefully log and retry or skip. — __
Watch for: If the initial concrete step (mocking the asyncio loop) fails to prove state persistence across multiple, simulated, sequential state changes, the entire premise of the 'memoryengine' as the single source of truth is invalidated. Kill criterion: If the system cannot reliably and deterministically transition from one structured state (e.g., H1: Inconclusive) to the next (e.g., H1: Supported) based on simulated evidence, it indicates a fundamental flaw in the state management layer that cannot be solved by adding more LLM calls.