
Personal Knowledge Sovereignty Interface (PKSI)
How can I see exactly which sources contributed to each step of an AI synthesis of my knowledge?
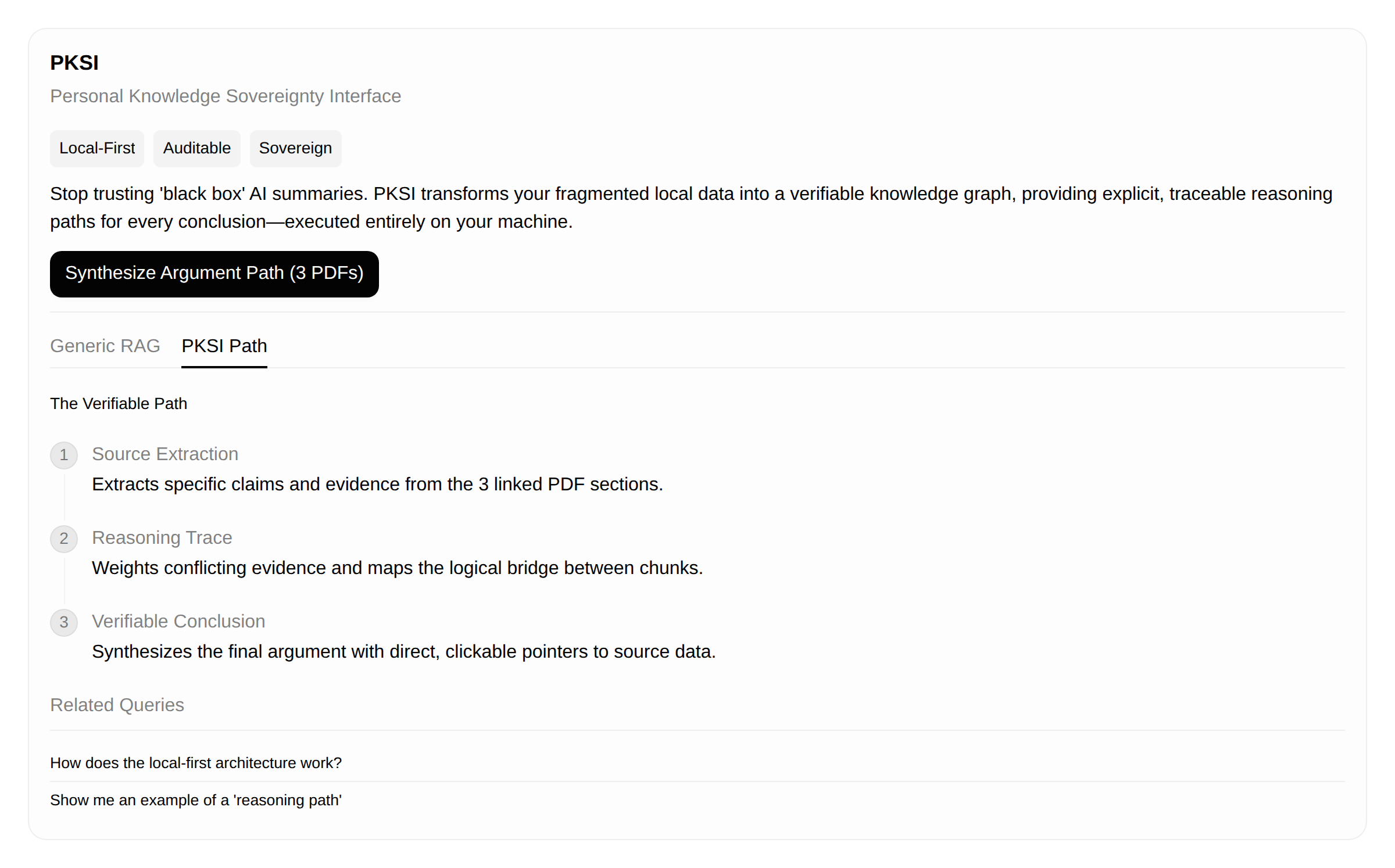
A local-first system ingests your fragmented personal knowledge (PDFs, notes, code) and synthesizes arguments while displaying a citation map showing which source chunks contributed to each conclusion step. The system traces the exact reasoning path through your connected data, displaying source chunks and the weighted connection that led to each output. This ensures you maintain full auditable control over how your data is processed and used.
Process flow
Who it's for
Knowledge workers and independent researchers who rely on multiple, non-corporate digital tools and require verifiable provenance for their arguments.
Why they need it
Users struggle with fragmented knowledge management and the increasing loss of autonomy/control over their data when using SaaS tools. They need a system that not only organizes knowledge but guarantees they maintain full, auditable control over the processing and output.
What it is
A decentralized, graph-based orchestration layer that connects local data silos into a unified, queryable knowledge structure. The core output is a controllable, transparent interaction layer built on top of it.
How it works
The system ingests local data sources. Instead of aiming for a universal 'Auditable Query Interface,' the MVP will focus on a single, highly constrained use case: Synthesizing the argument path for a specific technical debate by comparing 3 linked PDF sections. When a query is run, the system must trace the exact path of reasoning through the connected data chunks, displaying a citation map showing which piece of source data contributed how to each step of the synthetic output. This process is executed entirely locally.
Differentiation
Unlike generic directory tools like 's1' or corporate wikis like 's2', this system prioritizes personal data sovereignty and verifiable reasoning paths. Unlike standard RAG architectures, we don't just provide sources; we provide an explicit, traceable, weighted argument path for every conclusion, directly addressing the gap of 'verifiable, path-dependent knowledge synthesis for the individual user.'
Implementation sketch
- Phase 1: Build robust connectors/ingestors for 3 core local sources (e.g., Obsidian, local PDFs, Git repos) with verifiable chunk indexing.
- Phase 2: Implement the core graph logic, mapping relationships, but critically, tagging every relationship edge with its source chunk ID and confidence score.
- Phase 3: Develop the MVP: A constrained query interface focused only on comparing 3 linked PDF sections, displaying the step-by-step citation map.
First step: Select one specific, constrained use case (e.g., 'Comparing arguments in three specific academic PDFs') and build a proof-of-concept pipeline using only local file reading and a single, well-defined retrieval mechanism to validate the path-tracing concept.
Remaining risks
- The 'verifiable argument path' tracing mechanism fails to scale beyond the highly constrained MVP scope (3 PDFs). The complexity of tracking causality across different data types (PDF vs. Obsidian vs. Git) remains an exponential engineering challenge. — Focus initial engineering efforts on building a robust, abstract 'causality layer' that models the relationship between data chunks, rather than the data chunks themselves. Treat the data ingestion as a standardized input format for this layer, isolating the graph logic from the heterogeneity of the source connectors.
- User adoption stalls because the initial setup/indexing process (Phase 1 & 2) is perceived as a significant, time-consuming manual chore, despite the promise of 'autonomy.' The cognitive load of becoming a 'data architect' outweighs the perceived benefit of the final output. — Shift the initial marketing/pitch focus from the power of the graph to the speed of setup. Develop a 'Zero-Touch Indexing' feature where the system automatically suggests and prioritizes the most relevant 3-5 sources based on the user's recent activity, making the initial setup feel guided rather than overwhelming.
- The core value proposition of 'verifiable provenance' is undermined by the inherent limitations or hallucinations of the underlying local LLMs. If the LLM fabricates a step in the argument path that looks correct but is factually unsupported by the source chunks, the entire trust mechanism collapses. — Implement a 'Confidence Threshold' display. For every step in the argument path, the system must display not just the source chunk, but a quantified confidence score derived from the LLM's internal certainty regarding the connection. If the confidence drops below a set threshold, the path must be flagged as 'Inferred/Low Confidence' rather than presented as fact.
Watch for: Any indication from early user testing that users are more concerned with the ease of initial data connection than with the quality of the final synthesized argument. This signals that the initial friction point is setup, not reasoning. Kill criterion: If the team cannot demonstrate a stable, low-latency pipeline that reliably traces a multi-step, verifiable argument path across three distinct, non-trivial data types (e.g., a PDF, a markdown file, and a code snippet) within a single, defined use case, the technical risk is too high to proceed without a major architectural pivot.
Sources the council used
Real-world evidence that grounded this idea — judge it for yourself.