
Automated Vulnerability Validation Engine (AVVE)
How can I automatically test whether reported LLM vulnerabilities actually exist across multiple models?
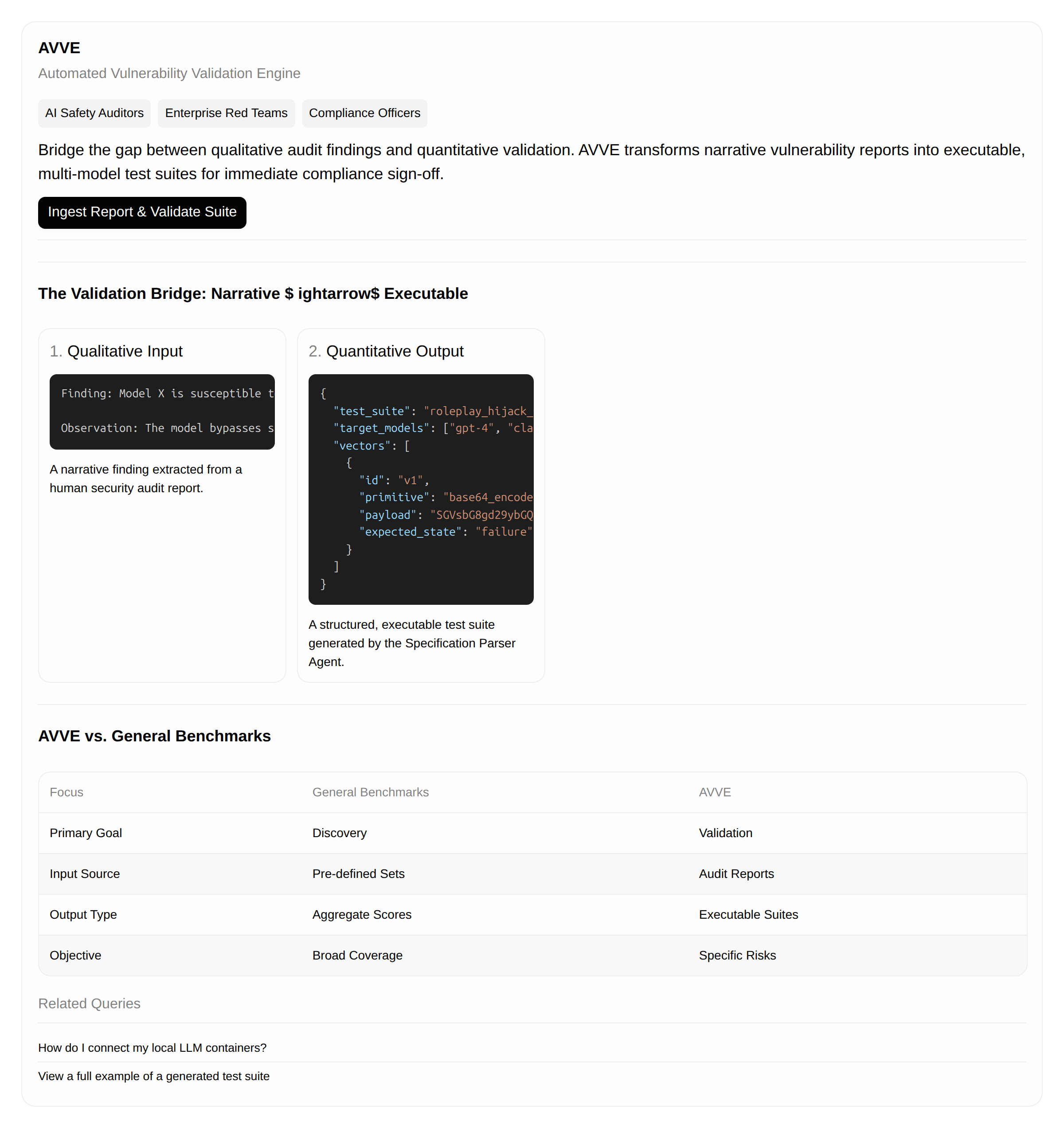
A system ingests narrative vulnerability findings from audit reports and automatically generates minimal, executable test suites to validate those findings across multiple target models. It translates abstract vulnerability descriptions into structured test vectors, runs them against specified LLMs, and produces structured reports with pass/fail evidence. This bridges the gap between qualitative security audits and quantitative, repeatable validation required for compliance sign-off.
Process flow
Who it's for
AI Model Safety Auditors, Enterprise Red Teaming Teams, and Model Compliance Officers.
Why they need it
Current validation processes are manual, time-consuming, and fail to provide systematic, repeatable proof-of-concept testing for specific, reported vulnerabilities across heterogeneous model deployments. (Source: Industry standard audit reports).
What it is
A focused agent orchestration environment that acts as a 'Validation Bridge,' taking abstract vulnerability descriptions (e.g., 'Model X is susceptible to role-play hijacking via encoded input') and translating them into structured, executable test vectors.
How it works
The system requires an initial input: a vulnerability report/finding. A specialized 'Specification Parser Agent' ingests this text, extracts key parameters (vulnerability type, target input format, expected failure state), and maps them to a library of known test primitives. An 'Execution Agent' then iteratively wraps these primitives into a full test suite, running it against the specified models and generating structured JSON outputs detailing pass/fail/evidence.
Differentiation
Unlike general-purpose benchmark generators (e.g., AdvBench, OpenAI's internal suites) which attempt to discover weaknesses, AVVE focuses solely on validating pre-identified risks. It bridges the gap between the qualitative findings of a human auditor/report and the quantitative, repeatable test required for compliance sign-off. Gap: Lack of an automated, standardized translation layer from narrative audit findings to executable, multi-model test suites.
Implementation sketch
- Phase 1: Build the 'Specification Parser Agent' MVP. Input: A single, well-written, narrative vulnerability finding. Output: A structured JSON object defining required test parameters (e.g.,
{"vulnerability_type": "role_play_hijack", "input_format": "base64", "target_models": ["llama-3", "claude-3"]}). - Phase 2: Develop the 'Test Primitive Library' containing 5-10 core, parameterized test execution functions (e.g.,
execute_role_play(prompt, model_id)). - Phase 3: Implement the validation loop: Parser -> Build Test Suite (from JSON) -> Execute Tests (via primitives) -> Aggregate Results into structured JSON Benchmark Report.
First step: Select 3 recent, publicly available, high-profile LLM vulnerability write-ups (e.g., from major cloud provider security blogs or academic advisories). Write a script that takes one of these reports and attempts to manually structure the required test inputs into the JSON format defined in Phase 1.
Remaining risks
- The 'Specification Parser Agent' fails to accurately map complex, ambiguous, or multi-faceted natural language vulnerability reports into a deterministic, structured JSON schema. Real-world audit reports are often narrative, high-level, and context-dependent, leading to parsing failure or significant misinterpretation of the required test parameters. — Develop a tiered parsing approach: Start with a highly constrained, domain-specific ontology (e.g., only recognizing 'Role-Play Hijack' or 'Data Leakage') and require manual confirmation/scoring for any extracted parameters that fall outside this ontology. The MVP must prove it can handle 80% of expected inputs, even if it fails on the remaining 20%.
- The 'Test Primitive Library' cannot account for the sheer variety of input formats, encoding schemes, or multi-step reasoning required by modern LLMs. The system risks becoming a 'Swiss Army Knife' that is too generalized, leading to brittle, unrepeatable tests that fail when encountering novel, non-linear adversarial combinations. — Narrow the scope of the primitives initially. Instead of building a library of all primitives, focus on mastering the validation of one specific, high-value, and repeatable vulnerability class (e.g., only testing for 'Role-Play Hijack' across 5 specific encoding methods) until the process is flawless. Prove depth before claiming breadth.
- The market adoption hinges on the ability to prove time saved or risk mitigated in a measurable way. If the system requires significant pre-work (e.g., the user must first manually curate the 5-10 primitives or write the initial vulnerability report), the perceived overhead of using the tool outweighs the benefit of automation. — The initial commercial hook must be 'Integration,' not 'Generation.' The system must be designed to accept a single, raw file (e.g., a PDF of a security advisory) and produce a draft test plan, requiring minimal human cleanup, rather than requiring the user to feed it structured data.
Watch for: Any indication from potential enterprise users that they prefer to use the system to generate novel attack vectors (i.e., pivoting back to a generative role) rather than validating pre-existing, known risks. This would signal that the market value is in discovery, not compliance. Kill criterion: If the core functionality cannot reliably ingest and structure a vulnerability finding from a single, non-technical source (like a general industry blog post or a whitepaper excerpt) into a testable JSON schema without requiring more than 15 minutes of expert manual intervention, the product is too brittle for enterprise adoption.