
Advisory Risk Copilot for AI Trading Strategy Validation
How do I test if my AI trading strategy will survive market stress?
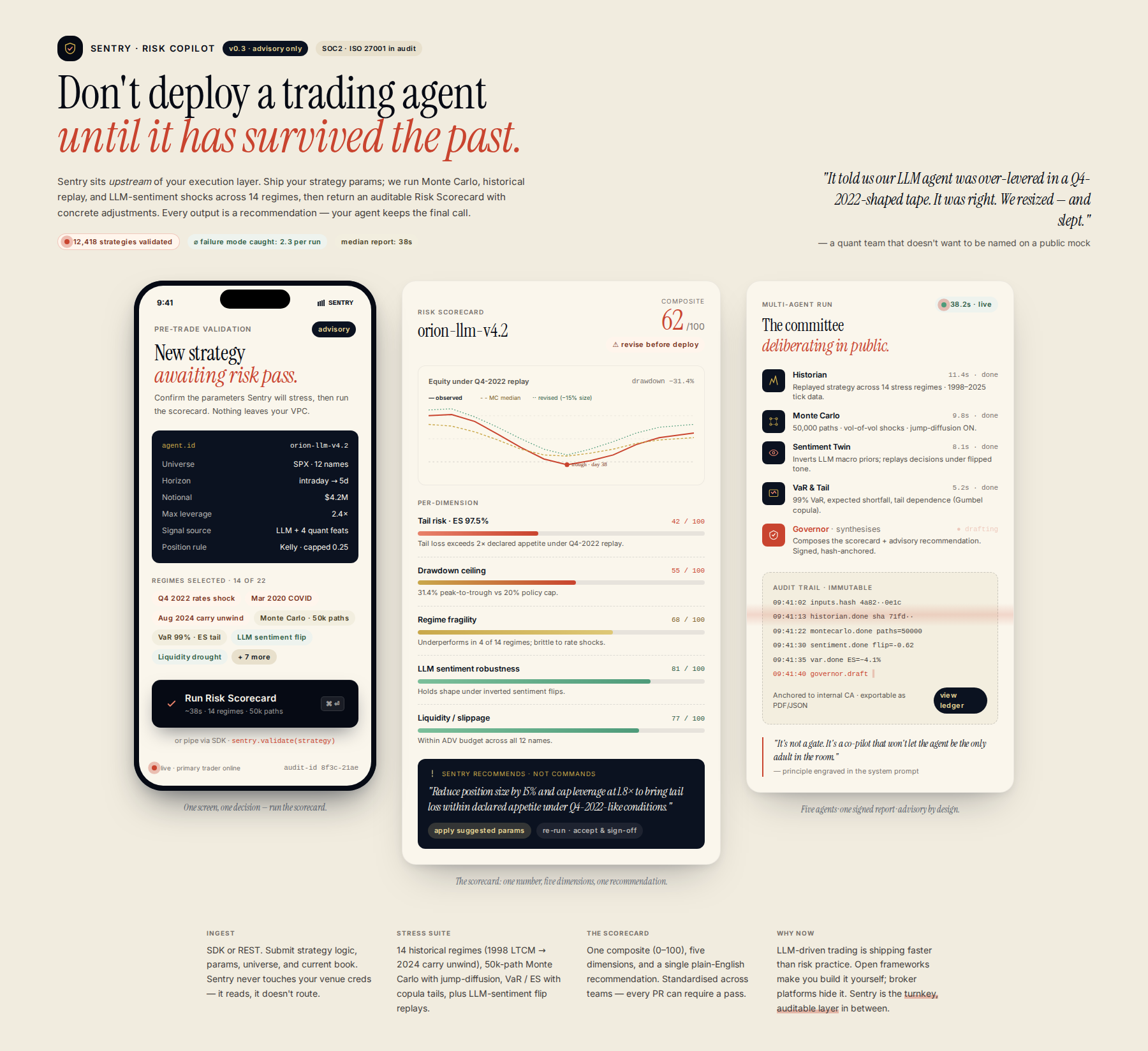
Simulate your strategy against historical market regimes and predicted volatility shifts using multi-agent risk models. A pre-deployment validation layer runs Monte Carlo, VaR, and LLM-sentiment stress tests to identify failure points before execution. The system generates an actionable risk scorecard with specific recommendations—e.g., 'Reduce position by 15% due to tail risk'—making the safety assessment measurable and auditable.
Process flow
Who it's for
AI/LLM developers building trading agents; quantitative researchers needing rigorous pre-deployment validation.
Why they need it
LLM-powered systems struggle with robust, real-time risk management during volatility, and developers lack a standardized, high-fidelity tool to validate risk protocols before deployment.
What it is
A dedicated, modular, multi-agent risk validation layer that operates upstream of execution, providing mandatory pre-trade risk reports and actionable governance recommendations.
How it works
The system ingests the proposed trading parameters and strategy logic from primary trading agents. Instead of forcing an override, the Risk Copilot runs these parameters through a suite of advanced, configurable risk simulations (e.g., Monte Carlo, Historical Simulation, VaR stress-testing). It then generates a comprehensive, auditable 'Risk Scorecard' detailing potential failure points, suggesting necessary adjustments (e.g., 'Reduce position size by 15% due to high tail risk exposure during Q4 2022-like conditions'). All output is a recommendation, not a command.
Differentiation
Unlike open-source frameworks or platforms that require manual integration of risk logic, this system provides a turnkey, best-in-class, and auditable risk assessment layer. It synthesizes multi-modal stress testing—combining historical market data with LLM-derived sentiment shifts—into a single, standardized pre-trade validation report, filling the gap where existing solutions lack standardized, synthesized advisory intelligence.
Implementation sketch
- Develop a standardized API endpoint/middleware layer that accepts proposed trade parameters for simulation, acting as a 'Validation Gate'.
- Implement the Risk Copilot using agentic architecture, leveraging 'memoryengine' to ingest and parameterize failure modes from historical market data and user-provided stress scenarios.
- Build the initial suite of mandatory risk checks (VaR, max drawdown) and develop the user-facing 'Risk Scorecard' dashboard, focusing on recommendation clarity rather than enforcement.
First step: Draft the OpenAPI specification (Swagger/YAML) for the 'Validation Gate' API endpoint, defining the exact JSON payload structure required for trade parameters (e.g., asset list, proposed size, time horizon) that the Risk Copilot will consume for simulation.
Remaining risks
- The 'advisory' nature may be perceived as insufficient by sophisticated quant developers who require mathematical guarantees equivalent to proprietary, closed-source risk engines (e.g., those used by major hedge funds). — Focus marketing and early adoption efforts on proving the synthesis capability—the unique combination of LLM-derived sentiment stress tests with traditional VaR/Monte Carlo—as the primary differentiator, rather than claiming mathematical parity with proprietary systems.
- The required integration point ('Validation Gate') might face resistance from established financial APIs or brokerage connections that do not natively support or recognize this middleware abstraction, leading to implementation deadlock. — Develop a tiered integration strategy: initially target users who are building internal simulation environments, bypassing external brokerage APIs entirely to prove the core simulation engine's value first. Later, build connectors for major, accessible simulation endpoints.
- The complexity of modeling market regimes (e.g., combining historical data with LLM sentiment shifts) could lead to 'over-fitting' to past crises, resulting in a Risk Scorecard that is overly pessimistic or generates too many false positives, leading to user fatigue and dismissal. — Implement a dynamic confidence scoring mechanism on the Risk Scorecard itself. Instead of just flagging risk, the system must output a confidence level for its own prediction (e.g., 'High Tail Risk Detected: Confidence 85% based on 2008/2022 analogs').
Watch for: A lack of developer interest in the synthesis aspect (LLM + quant models). If developers only ask for standard VaR/drawdown checks, it proves the core value proposition is not unique enough, and the concept reverts to being a mere wrapper around existing libraries. Kill criterion: If early proof-of-concept testing reveals that the primary pain point is not the availability of risk checks, but the latency or computational overhead introduced by running the multi-modal simulation layer, the concept must pivot away from real-time pre-trade validation.
Sources the council used
Real-world evidence that grounded this idea — judge it for yourself.