
Secure Knowledge Synthesis via Heterogeneous Agent Federation
A decentralized framework enabling multiple local LLMs to collaboratively refine knowledge and improve safety benchmarks by providing verifiable, cross-domain synthesis without exposing private data.
Process flow
classDef startEnd fill:#ccf,stroke:#333,stroke-width:2px;
class A,H startEnd;
Who it's for
Academic AI Research Groups & Regulated Industries (Pharma, Finance)
Why they need it
Current state-of-the-art multi-agent systems are siloed and lack verifiable, secure mechanisms for synthesizing insights derived from heterogeneous, proprietary data sources. This failure point—the inability to prove data provenance across secure boundaries—is critical in regulated fields.
What it is
A 'Federated Agent Training' platform that orchestrates multiple specialized, locally-run LLMs (via frameworks like AgentCollective) to solve complex, multi-faceted research problems collaboratively, culminating in a verifiable 'Knowledge Artifact'.
How it works
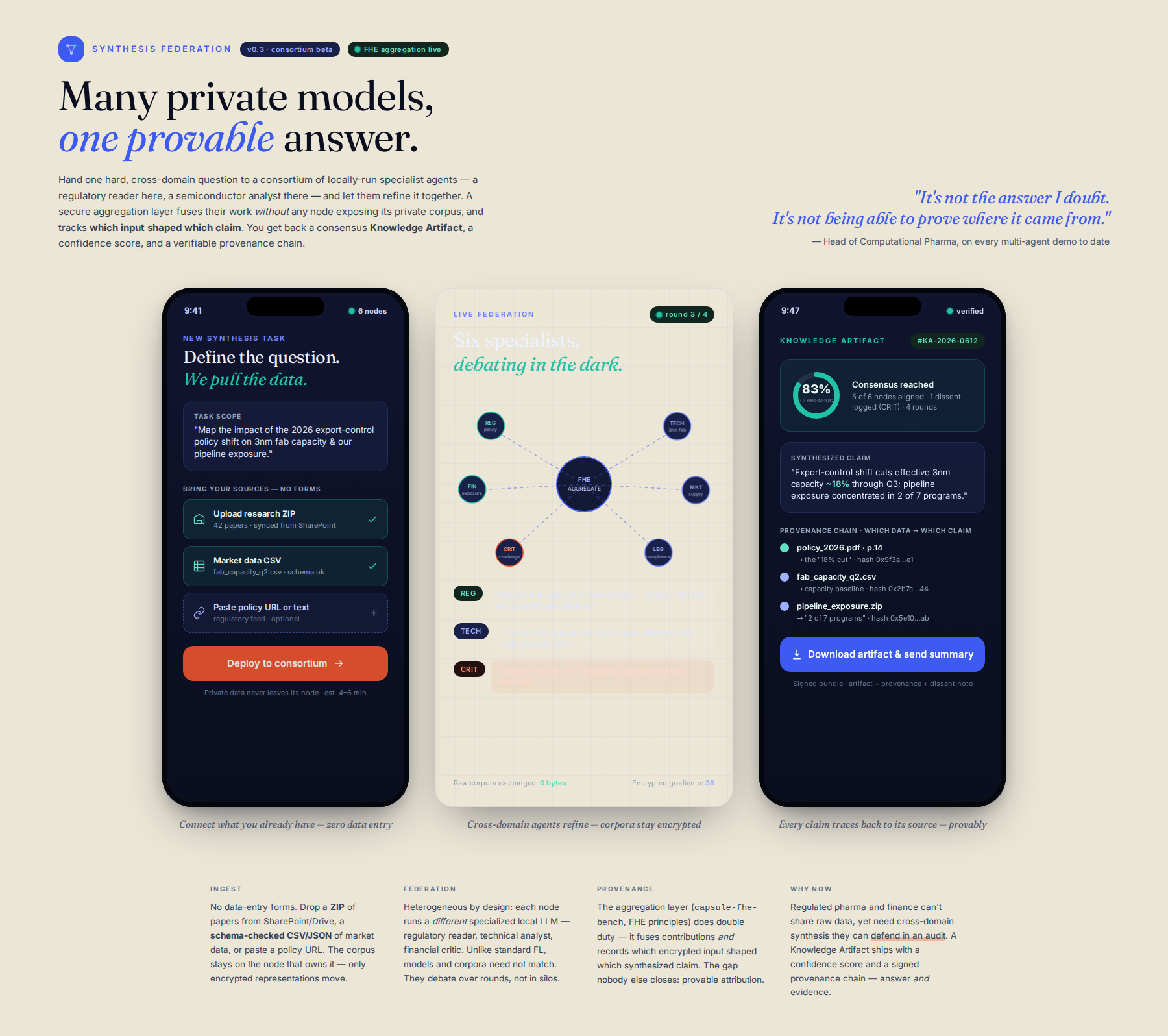
- Define a complex research task requiring diverse viewpoints (e.g., analyzing policy shifts + semiconductor data). 2. Deploy the task to a consortium of nodes, each running a different specialized LLM/agent setup (e.g., one agent for regulatory reading, one for technical deep dives). 3. Use a secure aggregation layer (leveraging FHE principles, 'capsule-fhe-bench') not just for synthesis, but explicitly to track data provenance across the inputs. 4. The system outputs a synthesized, consensus-driven 'Knowledge Artifact' and a confidence score, along with a verifiable provenance chain.
Differentiation
Unlike simple multi-agent orchestration, which keeps agents siloed, or pure FL, which often assumes homogeneous data/models, this focuses specifically on secure, cross-domain knowledge synthesis with mandatory provenance tracking. We solve the failure mode where existing systems cannot prove which private data contributed to which synthesized claim, a gap not addressed by existing solutions like 'agentcollective' or standard FL protocols.
Implementation sketch
- Prototype the agent communication layer to accept structured outputs from diverse local model endpoints (via local API hooks).
- Implement the 'Knowledge Artifact' structuring mechanism, forcing agents to cite source type AND the specific data segment/query that informed the output (Provenance Tagging).
- Develop a proof-of-concept 'Consensus/Conflict Resolution' module that flags contradictory outputs AND maps the conflicting provenance segments for mandatory human review, providing a confidence score.
First step: Identify and benchmark the latency overhead of adding a simple, standardized provenance metadata field (e.g., a cryptographic hash/ID) to the output structure of the 'agentcollective' framework when simulating three distinct, local model endpoints.
Remaining risks
- Computational Overhead Implosion: The combination of running multiple specialized, local LLMs concurrently, plus the computational overhead of Fully Homomorphic Encryption (FHE) for aggregation, plus the overhead of mandatory provenance tracking, creates a compounding computational burden. This overhead is likely to render the system unusable for any real-time or near-real-time application, making the value proposition purely academic. — Focus initial benchmarks solely on the data structure and provenance tagging mechanism's overhead against a simplified, non-FHE aggregation layer (e.g., secure multi-party computation using simpler additive secret sharing) to establish a performance baseline before tackling the full FHE complexity.
- Integration Fragility: The system relies on integrating diverse, proprietary, and potentially unstable local LLM endpoints via API hooks. Any significant change in the local model architecture, API versioning, or resource availability at the consortium level will cause the entire orchestration layer to fail catastrophically. — Develop an abstraction layer (a 'Model Adapter' pattern) that strictly enforces a minimal, stable input/output contract for all connected agents, decoupling the core orchestration logic from the specific technical details of any single LLM vendor or implementation.
- Semantic Over-Reliance: The 'Knowledge Artifact' is designed to be consensus-driven, but if the underlying specialized agents are trained on fundamentally contradictory or biased foundational datasets (e.g., one agent trained on Western policy, another on non-Western policy), the 'consensus' mechanism may simply institutionalize and legitimize a deeply flawed, yet technically verifiable, synthesis. — Mandate the development of a 'Bias Conflict Map' module that, upon flagging conflict, doesn't just point to the conflicting provenance segments, but also cross-references those segments against a curated, documented set of known systemic biases (e.g., geographical, temporal, ideological) to alert the human reviewer to the type of conflict, not just its existence.
Watch for: Any indication that a single, existing, non-federated, commercially available LLM endpoint (e.g., a single large model fine-tuned on diverse data) can achieve 90% of the required synthesis quality without the explicit, complex cross-domain orchestration and provenance layer. Kill criterion: If the initial benchmarking of the 'Model Adapter' layer (the abstraction layer) reveals an overhead exceeding 20% latency increase over the raw, un-orchestrated LLM output, the entire architecture is too fragile and computationally expensive to be viable for any industry use case.