
AI-Assisted Data Capture & Loss Prevention for SMBs
A mobile-first platform that uses AI to digitize manual, analog data sources (handwritten labels, paper manifests) into structured, actionable inventory records, providing immediate loss prevention insights for small businesses.
Can AI help me find missing or misplaced inventory items?
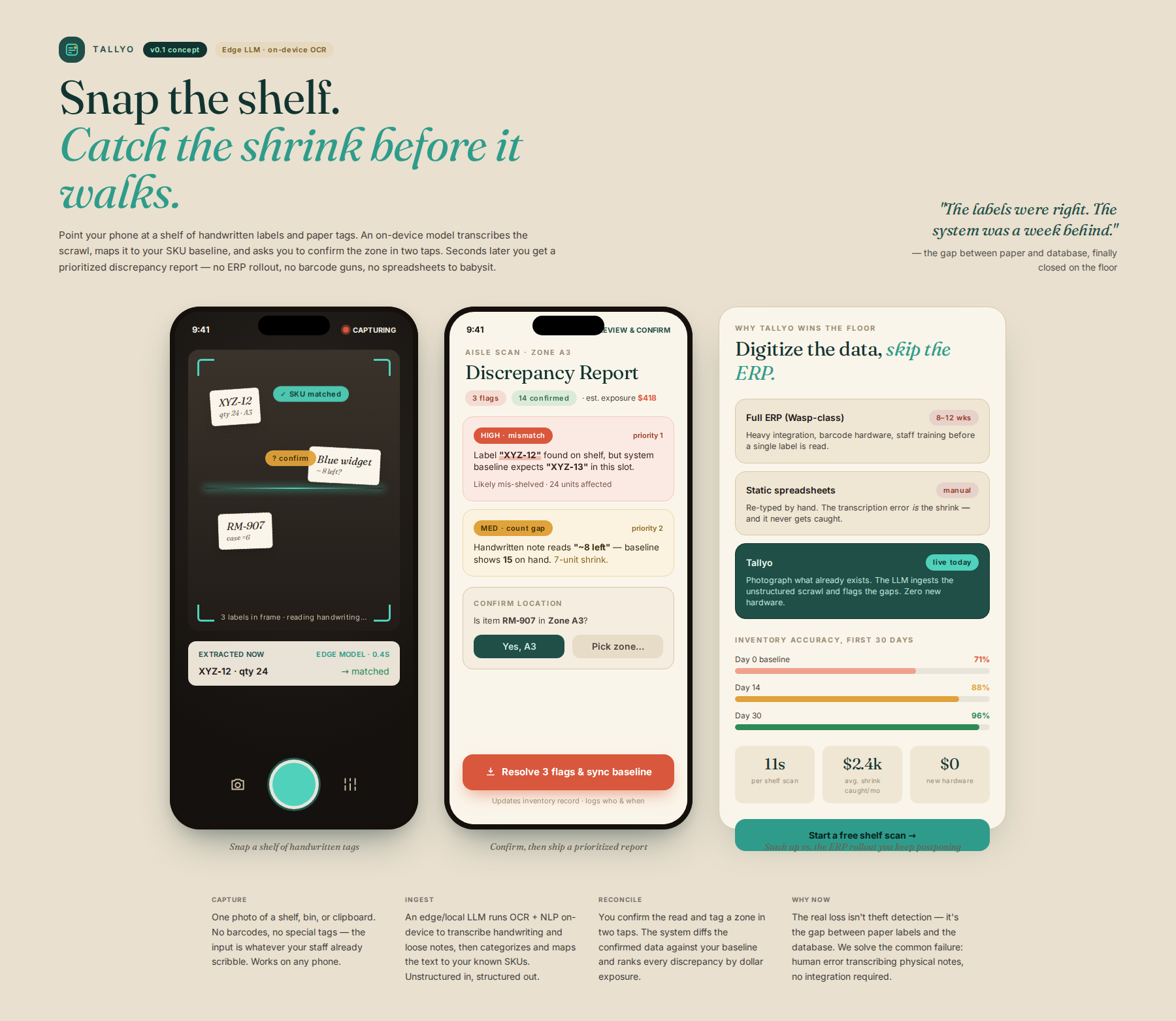
Yes—photograph physical labels or handwritten notes on your shelves and an AI system transcribes them, compares against your digital records, and flags discrepancies (e.g., 'Label XYZ found on shelf, but system shows XYZ-2'). The system focuses on digitizing the data you already have, not on complex vision. The output is an actionable discrepancy report that guides your loss prevention efforts.
Process flow
Who it's for
Small business owner/manager responsible for physical inventory integrity.
Why they need it
SMBs need simple inventory help, but current tools are either too complex (ERP) or rely on imperfect manual data entry (spreadsheets/paper). The immediate pain point is the friction and error introduced when bridging the physical world (paper/labels) to the digital record.
What it is
A mobile application that guides the user to photograph physical labels or handwritten notes near inventory items. An integrated LLM then transcribes, categorizes, and structures this unstructured text data, comparing it against a digital SKU baseline to flag discrepancies.
How it works
- User takes a photo of a shelf/area containing physical labels or handwritten notes. 2. The mobile agent (leveraging a local/edge LLM for OCR/NLP) processes the image to extract text and attempt to map it to known SKUs. 3. The system prompts the user to confirm the extracted data and identify the item's location/zone. 4. It compares the extracted/confirmed data against the stored baseline and generates a prioritized 'Discrepancy Report' (e.g., 'Label 'XYZ-12' found, but system expects 'XYZ-13'').
Differentiation
We pivot from complex vision detection to simple data digitization. Unlike full ERP systems (Wasp), which require massive upfront integration, or static sheets, this tool solves the critical gap of unstructured data ingestion. It minimizes reliance on perfect object recognition by focusing on the most common failure point: human error when transcribing physical labels or notes.
Implementation sketch
- Develop a proof-of-concept OCR/NLP pipeline capable of transcribing and normalizing text from varied sources (handwritten, printed labels) into structured JSON.
- Build a simple mobile state machine that guides the user through 'Photo -> Extract -> Confirm -> Report,' minimizing steps.
- Design a dashboard view that prioritizes 'Actionable Discrepancies' (e.g., 'Label Mismatch,' 'Missing Zone Tag') over raw count variances.
First step: Spend one full day prototyping the OCR/NLP pipeline using a small, controlled dataset of 50 handwritten/printed labels from a local SMB, aiming for a 90% accuracy rate on basic SKU extraction, ignoring the mobile UI for now.
Remaining risks
- The assumed accuracy of OCR/NLP on real-world, varied, and damaged physical labels (e.g., faded ink, crumpled paper, multiple overlapping labels) will be significantly lower than the 90% target, leading to a low-trust user experience. — Implement a multi-stage confidence scoring system for every extracted piece of data. If the confidence score for a critical field (like SKU) is below a threshold (e.g., 80%), the system must force the user to manually verify that specific field before proceeding, rather than accepting the AI's best guess.
- The 'discrepancy' report, while actionable, might fail to capture the root cause of the data gap (e.g., the user mislabeled the item initially, or the SKU system itself is outdated). The tool risks becoming a sophisticated 'symptom reporter' without providing systemic process improvement advice. — In the reporting phase, add a mandatory 'Process Check' prompt. When a discrepancy is flagged, the system must prompt the user with a set of guided, non-technical questions like: 'Was this item labeled correctly at the source?', or 'Is the SKU system itself up-to-date for this product line?' to surface process failures, not just data entry errors.
- The dependency on 'local/edge LLM' for OCR/NLP, while technically sound for privacy, introduces significant computational overhead and potential latency issues on older or lower-powered mobile devices common among SMB owners. — For the MVP, de-scope the 'local LLM' requirement entirely. Instead, build the initial workflow around a simple, cloud-based API call for the OCR/NLP step, acknowledging the latency risk upfront. This allows for rapid iteration on the value (data capture) while deferring the technical constraint (local compute) until the core workflow is proven valuable.
Watch for: If early user testing reveals that users spend more time correcting the AI's extracted data than they do performing the audit itself, the core value proposition is flawed. Kill criterion: If initial user feedback indicates that the system requires more than three distinct steps (Photo -> Extract -> Confirm -> Report) to generate a single actionable insight, the process is too cumbersome for the target user.
Sources the council used
Real-world evidence that grounded this idea — judge it for yourself.