
Local LLM Agent Orchestrator for Conflict-Aware Academic Synthesis
How can I resolve conflicting claims across multiple research datasets?
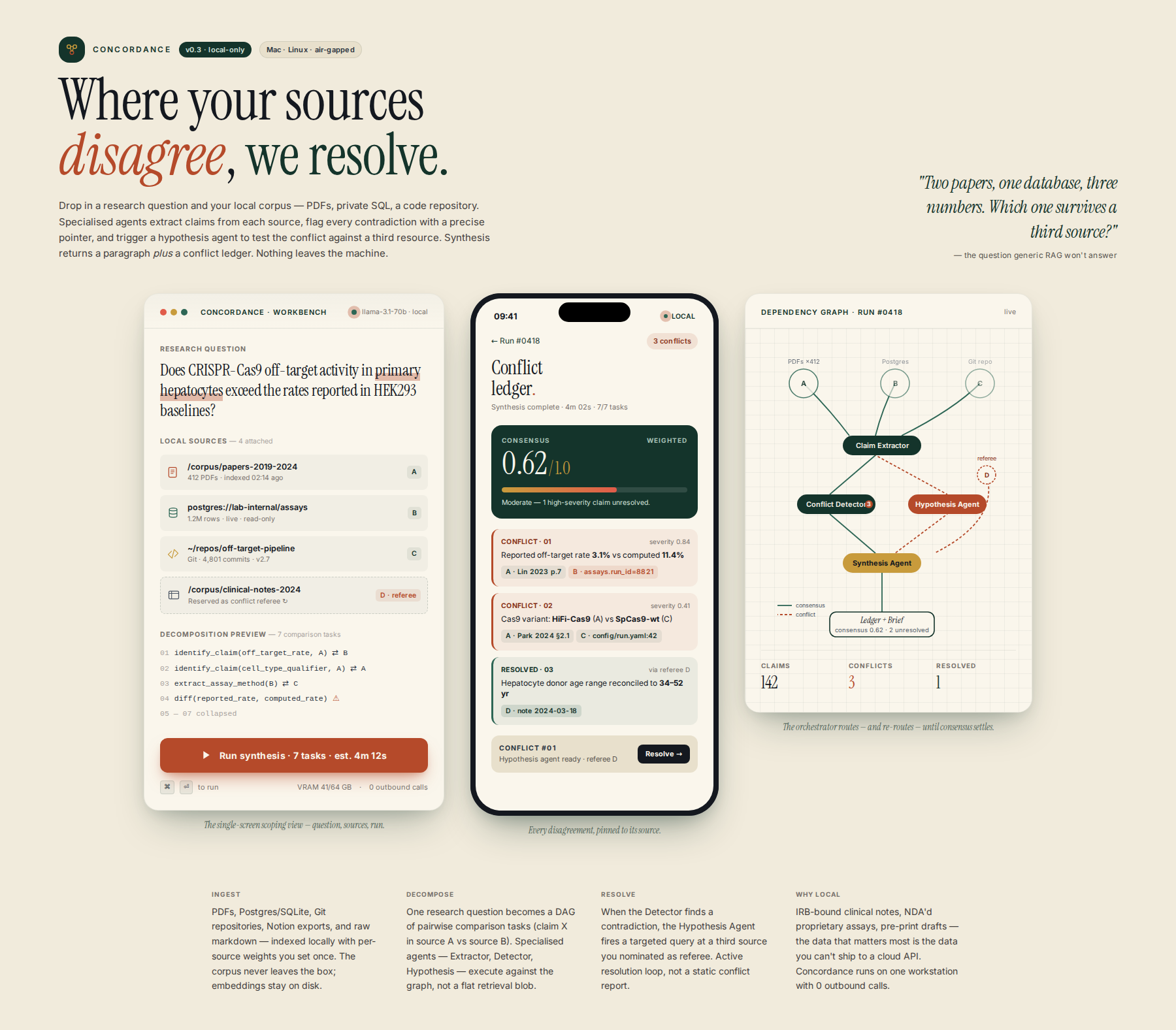
Deploy specialized agents to ingest data from siloed sources, extract and compare claims, and flag contradictions with source pointers and confidence scores. The system models conflict as its primary state and triggers a Hypothesis Generation Agent to attempt resolution by querying a third data source. This active, iterative approach moves beyond reporting conflicts to problem-solving.
Process flow
classDef startEnd fill:#ccf,stroke:#333,stroke-width:2px;
class A,H startEnd;
classDef process fill:#e6f7ff,stroke:#007acc,stroke-width:2px;
class B,C,D,F,G process;
Who it's for
Academic research teams, specialized R&D labs, or institutions dealing with proprietary/non-indexed, multi-source data repositories.
Why they need it
Current academic research often fails at the synthesis stage when confronted with conflicting or non-indexed data points (e.g., Dataset A claims X, Dataset B claims Not-X, and Dataset C provides mechanism Z). Existing tooling cannot reliably manage the context transfer and systematic conflict flagging required to resolve these deep contradictions using only local compute.
What it is
A specialized software layer ('Orchestrator') that ingests a high-level research question and multiple distinct, local data sources (e.g., local PDFs, private databases, specialized code repositories). It manages the workflow by explicitly routing agents to search, extract, and compare claims across these disparate sources.
How it works
The Orchestrator operates via a dependency graph: 1. Ingestion/Indexing: Agents index the provided local data sources. 2. Task Decomposition: The goal is broken into comparison tasks (e.g., 'Identify all mentions of X in A vs B'). 3. Agent Execution: Specialized agents (e.g., 'Claim Extractor Agent', 'Conflict Detector Agent') execute locally. 4. Verification: The final 'Synthesis Agent' does not just summarize; it must produce a structured output flagging all conflicts, providing the precise source pointers for each conflict, and calculating a consensus confidence score based on source weighting.
Differentiation
We move beyond general 'AI OS' hype by focusing on the Conflict Resolution sub-problem. Unlike generic ETL pipelines or knowledge graph construction tools (e.g., [KG_ID_123]), which typically report conflicts statically, our Orchestrator mandates an active, iterative resolution loop. The gap filled is the lack of a local middleware that automatically triggers a 'Hypothesis Generation Agent' to attempt to resolve identified contradictions by querying a third, specified local resource, moving the system from a reporting tool to an active problem-solving system.
Implementation sketch
- Redefine the state machine to model 'Conflict State' and 'Resolution Attempt' as primary states, rather than simple success/fail.
- Implement a 'Source Comparison Module' that forces agents to pass not just data, but structured triples (Subject-Predicate-Object) along with their originating source ID.
- Develop a weighted confidence scoring mechanism that penalizes synthesis paths relying on single, uncorroborated sources.
First step: Develop a minimal viable state machine prototype (using Python/Graphviz) that models the transition from 'Conflict State' to 'Hypothesis Generation State' based on a fixed set of input triples, ignoring LLM calls initially to test the structural logic.
Remaining risks
- The 'Hypothesis Generation Agent' loop might enter an infinite or unproductive cycle of conflict detection and resolution attempts without external human intervention, leading to computational deadlock and wasted resources. — Implement a hard, configurable iteration limit (e.g., max 5 resolution attempts per conflict cluster) and a mandatory 'Stalemate Report' state that forces the system to pause and request user input or priority re-evaluation.
- The reliance on structured triple passing (S-P-O) across multiple, potentially heterogeneous local data sources (PDFs, databases) will fail when the underlying data structure is ambiguous or requires implicit domain knowledge the agents lack. — Develop a preliminary, non-LLM-based schema validation and normalization layer that runs before agent execution, forcing the user/system to map expected data types and relationships for the specific domain, thus constraining the LLM's search space.
- The 'consensus confidence score' calculation becomes a black box of proprietary logic, undermining the 'verifiable' claim. Users will treat it as an arbitrary score rather than a mathematically derived measure. — Make the confidence scoring mechanism fully auditable by requiring the system to output the exact mathematical formula and the weights applied for every single score calculation, allowing the user to trace the score back to the source inputs.
Watch for: Any instance where the system successfully resolves a conflict by proposing a hypothesis, but the user immediately rejects the hypothesis and cannot articulate why the system's proposed resolution was flawed, indicating the system is generating plausible but fundamentally incorrect 'guesses'. Kill criterion: If the system fails to execute the 'Source Comparison Module' successfully on a standardized, pre-vetted dataset (e.g., 10 known conflicting triples from a public domain source) more than 3 times in a row, indicating a systemic failure in deterministic state passing regardless of the complexity of the input.