
Contextual Memory Inference Engine: Unlocking Narrative Potential from Unlabeled Family Media
An inference-driven platform that uses advanced AI to generate rich, narrative timelines from disparate, messy family media, focusing on complex pattern recognition where explicit metadata fails.
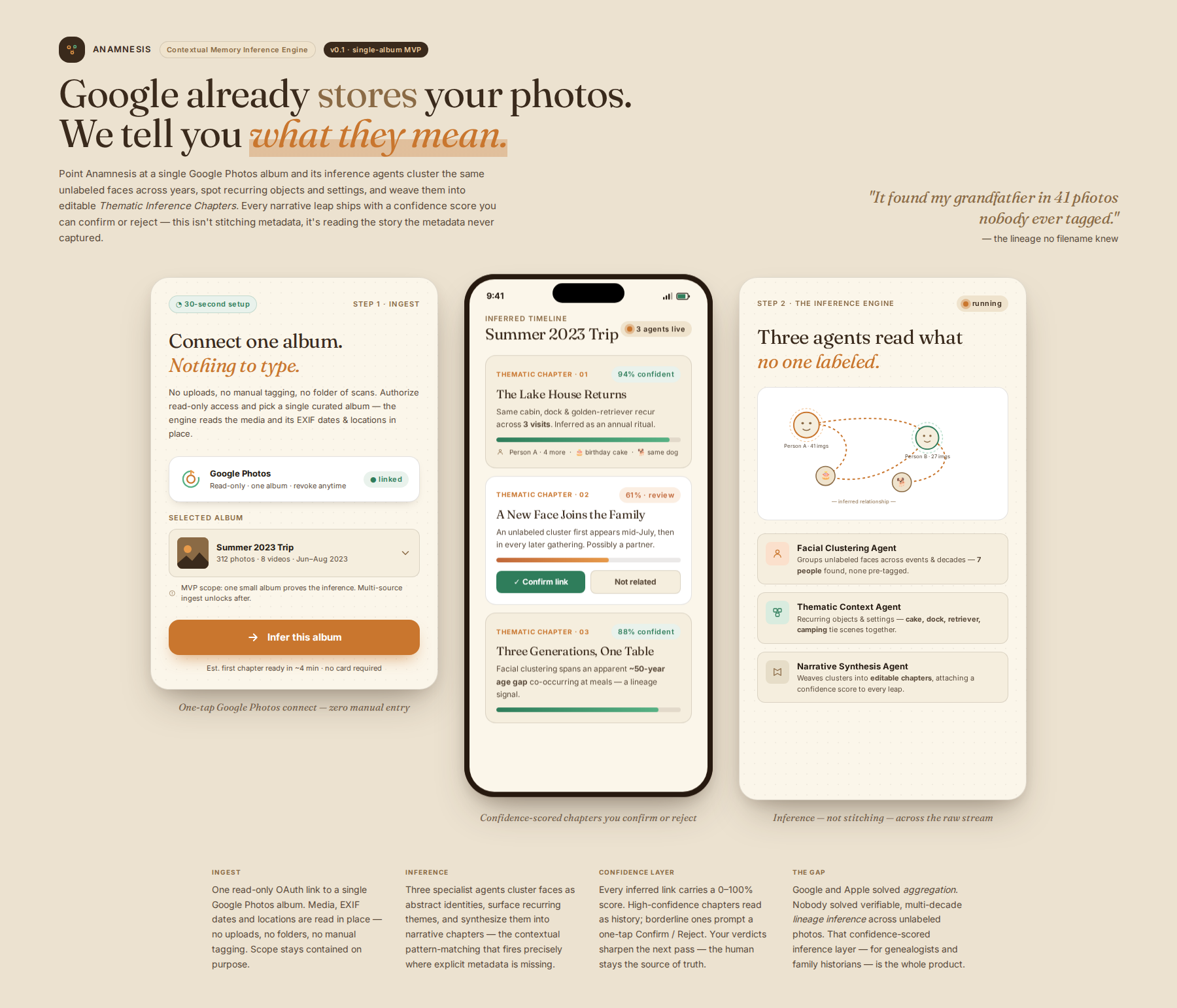
Process flow
Who it's for
Genealogy services and dedicated family historians with significant, unstructured digital archives.
Why they need it
Family digital memories are not just scattered; they are contextually under-indexed. Standard cloud services only aggregate files; they cannot reliably infer narrative connections from unlabeled faces, ambiguous locations, or thematic patterns across vast, disorganized collections, creating a critical bottleneck for genealogical research.
What it is
A specialized AI engine that moves beyond simple data stitching to perform inference—automatically generating 'Thematic Inference Chapters' by finding hidden relationships in raw, unlabeled media streams.
How it works
- Ingestion: User connects various sources (Google Photos API, local drives).
- Core Inference Engine: The system deploys specialized agents focused on inference: a 'Facial Clustering Agent' groups unlabeled faces across time/events; a 'Thematic Context Agent' identifies recurring objects, styles, or activities (e.g., 'birthday cake,' 'specific dog breed,' 'outdoors camping'); and a 'Narrative Synthesis Agent' weaves these inferred clusters into coherent, editable storylines.
- Output: A curated, navigable timeline that highlights inferred connections, presenting confidence scores for each narrative leap, allowing the user to validate the AI's suggestions.
Differentiation
We shift the focus from data aggregation (solved by Google/Apple) to contextual inference (the gap). Specifically, we solve the problem of lineage mapping across decades of unlabeled photos—a task requiring verifiable, multi-decade, multi-source pattern recognition that current commercial solutions do not offer. Our unique value is the confidence-scored inference layer built atop these clusters.
Implementation sketch
Prototype the 'Facial Clustering Agent' using open-source face embedding models (e.g., facenet) against a controlled, messy dataset to establish baseline clustering accuracy.
Develop the 'Thematic Context Agent' to identify and score common objects/activities across video frames and photos, linking them to temporal/geospatial anchors.
Build an interactive visualization layer that visually maps the confidence score alongside the narrative thread, making the AI's assumptions transparent to the end-user.
First step: Select a publicly available, messy, historical family photo dataset (e.g., from a university archive) and build a minimal proof-of-concept pipeline to run facenet embeddings and visualize the resulting cluster graph in a Jupyter notebook environment, proving the baseline clustering capability.
Remaining risks
- Data Ingestion/API Volatility: Reliance on third-party APIs (Google Photos, iCloud) means the entire system is vulnerable to sudden changes in authentication requirements, rate limits, or API deprecation, potentially halting data collection entirely. — Implement a modular, abstract data connector layer that treats each API as a distinct, replaceable module. Prioritize local file ingestion and offline data processing capabilities as a fallback, treating cloud connections as 'enhancements' rather than core requirements.
- Inference Drift/Bias Amplification: The AI models (Facial Clustering, Thematic Context) are trained on historical data that inherently contains biases (e.g., underrepresentation of certain groups, cultural biases in labeling). If the model amplifies these biases, the 'narrative' generated will be factually misleading or discriminatory. — Mandate a 'Bias Audit Layer' in the output. For every inferred connection, the system must flag potential demographic or cultural blind spots, requiring the user to explicitly validate the inference against known contextual knowledge (e.g., 'This cluster appears disproportionately focused on one socioeconomic group; verify context').
- Computational Cost and Latency: Running advanced, multi-agent inference (Facenet embeddings, thematic analysis across massive datasets) is computationally expensive. Processing large, multi-decade archives could lead to prohibitive processing times and cloud compute costs, making the service unusable for the average user. — Introduce tiered processing levels: Tier 1 (Quick Scan) runs only metadata and basic clustering; Tier 2 (Deep Inference) runs the full, costly inference suite and requires premium payment; Tier 3 (Historical/Research) is reserved for institutional/genealogy clients who can absorb the cost.
Watch for: If early prototypes fail to achieve a stable, reproducible clustering accuracy (e.g., <75% recall) on a standardized, messy, out-of-domain dataset, it signals that the underlying computer vision/ML problem is too ill-posed for a consumer product. Kill criterion: If the cost to process a standardized, medium-sized (10,000 photo/video) archive exceeds a predetermined threshold (e.g., $50) without generating a demonstrable, unique, and highly valuable insight that justifies the cost, the core technical premise is economically unviable.
Sources the council used
Real-world evidence that grounded this idea — judge it for yourself.