
Structured Knowledge Graph Builder from User-Provided Transcripts
A platform that ingests raw text transcripts (from videos, lectures, meetings) and autonomously transforms them into a multi-modal, interconnected, and searchable knowledge graph for professionals.
How do I turn hours of video into a searchable knowledge graph?
A platform ingests raw transcripts and autonomously transforms them into interconnected knowledge graphs using specialized agents for topic modeling and relationship identification. The system deploys a multi-agent pipeline that identifies entities, relationships, and causality, populating a queryable graph database. You can then run complex queries to find all connections between specified concepts across your uploaded materials.
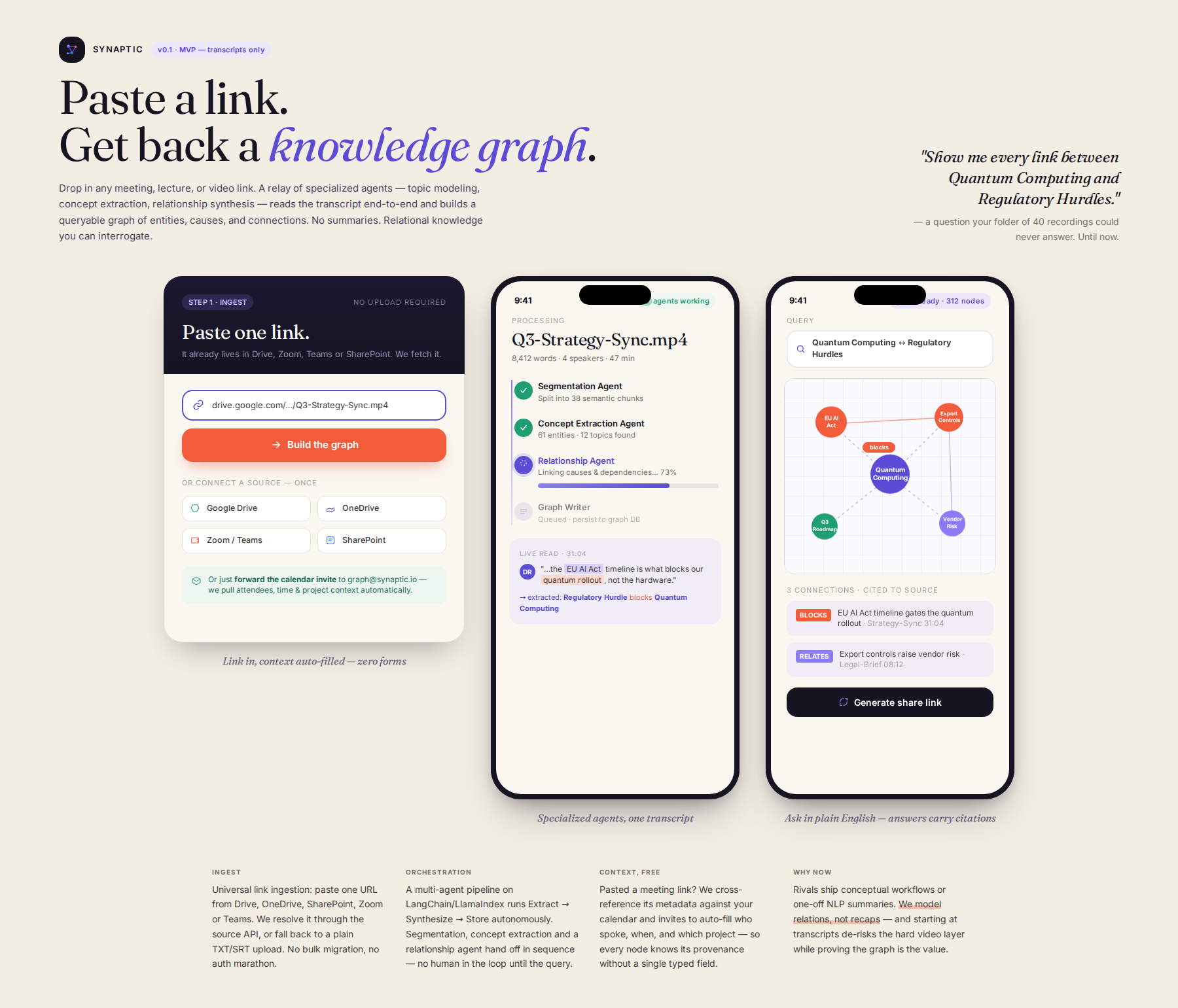
Process flow
Who it's for
Knowledge worker trying to synthesize video content
Why they need it
Professionals struggle to turn hours of passive video watching into a searchable, actionable library of expert knowledge, as highlighted by the concern to turn passive viewing into an actionable library.
What it is
A comprehensive, agent-orchestrated pipeline designed to ingest user-provided transcripts, segment, identify core concepts, and synthesize relationships into a structured, queryable knowledge graph.
How it works
- Ingestion: User uploads raw transcripts (TXT, SRT, etc.). 2. Multi-Stage Agents: The system deploys specialized agents (e.g., Topic Modeling Agent, Concept Extraction Agent, Relationship Agent) powered by industry-standard orchestration frameworks (e.g., LangChain/LlamaIndex). 3. Synthesis & Graphing: Agents process transcripts, identifying key entities, relationships, and causality. These structured facts populate a graph database. 4. Output: The user receives a dashboard allowing complex queries (e.g., 'Show me all connections between 'Quantum Computing' and 'Regulatory Hurdles' mentioned in uploaded materials from last quarter').
Differentiation
Existing solutions are conceptual workflows or point solutions. Our difference is the autonomous, multi-agent orchestration that handles the entire 'Extract -> Synthesize -> Store' loop end-to-end, moving beyond simple NLP summaries into relational knowledge modeling. By focusing the MVP on transcripts, we de-risk the initial, complex video ingestion layer, allowing us to prove the core value of relational modeling first.
Implementation sketch
- Build the core orchestration logic using LangChain/LlamaIndex to manage the sequence of specialized processing agents.
- Develop a dedicated Knowledge Graph Schema optimized for concept relationship mapping (Entity A $ o$ Relationship $ o$ Entity B) and implement the schema in Neo4j.
- Integrate a user-facing query interface that traverses the graph, allowing natural language input to complex relational outputs.
First step: Set up a sandbox environment with LangChain/LlamaIndex and a local Neo4j instance. Write a proof-of-concept script that takes a single sample transcript and successfully executes a sequence: (1) Extract N entities, (2) Define 3 relationships between them, and (3) Write those structured triples into Neo4j.
Remaining risks
- The quality and specificity of relationship extraction remain highly dependent on the domain context provided by the user, leading to inconsistent or hallucinated relationships in the graph. — Implement a mandatory 'Domain Context Prompting' step where the user must select or provide 3-5 core domain concepts upfront. The orchestration layer must then prepend these concepts to every agent prompt to constrain the LLM's extraction scope and improve grounding.
- The complexity of the query interface might mask underlying data quality issues. Users might successfully query the graph, but the results will be superficially correct yet functionally useless (e.g., showing connections that are technically true but contextually meaningless). — Introduce a 'Confidence Scoring' layer on the graph nodes/edges. When the query returns a result, it must display the system's confidence score for the extracted relationship (e.g., 'Connection between X and Y: Confidence 78% - Based on direct mention'). This manages user expectations about data reliability.
- The system, while excellent at structured extraction, may fail to capture the nuance of expert discussion—the implicit assumptions, the counter-arguments, or the underlying consensus shift—which are crucial for high-level knowledge work. — Develop a specialized 'Divergence/Consensus Agent' that specifically scans for contrasting viewpoints within the text (e.g., 'Some experts argue X, while others suggest Y'). This forces the graph to model debate structure rather than just factual connections.
Watch for: If initial user testing shows users spending more time manually refining the extracted relationships or questioning the system's interpretation than they spend querying the graph, the core value proposition of 'autonomy' is failing. Kill criterion: If the system cannot reliably process a standard, high-quality, domain-specific academic paper transcript (e.g., a Nature/IEEE paper) and populate the graph with at least 10 distinct, verifiable relationships without manual intervention or significant prompt engineering, the core extraction logic is fundamentally flawed for the target professional user.
Sources the council used
Real-world evidence that grounded this idea — judge it for yourself.