
Standardized Multi-Agent Context Decay Benchmarking Suite (MACDS)
How do I measure how much multi-agent context memory efficiency degrades under production loads?
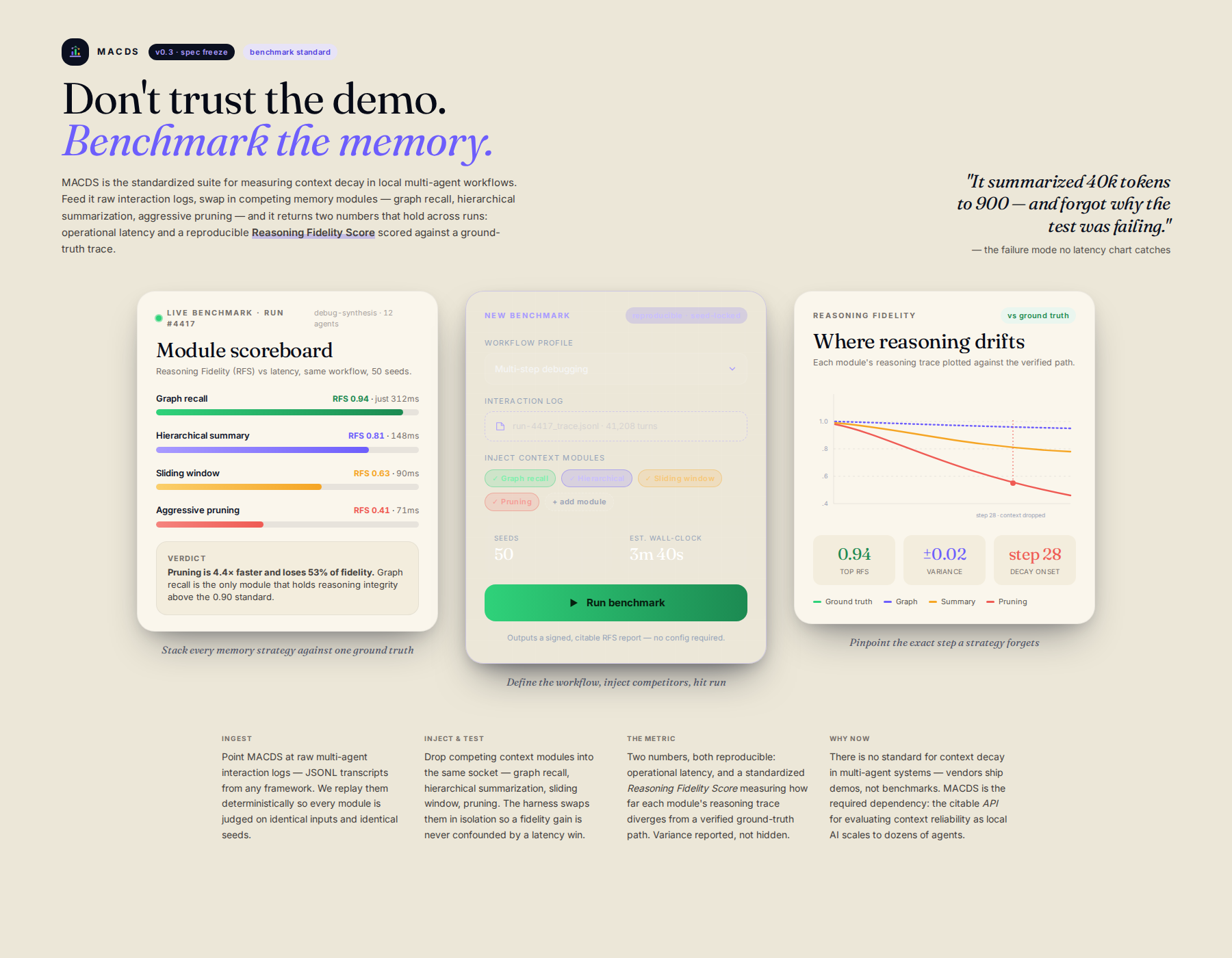
A foundational benchmarking suite standardizes how to measure context memory efficiency and reasoning integrity in complex, local, multi-agent workflows. It injects competing context management strategies into defined workflows, measures operational latency and semantic fidelity, and generates reproducible benchmark reports. This establishes an industry standard for evaluating multi-agent context reliability, moving from ad-hoc measurements to measurable, standardized metrics.
Process flow
Who it's for
AI Research Labs, LLM Infrastructure Vendors, and Enterprise AI Deployment Teams.
Why they need it
The rapid scaling of multi-agent systems generates context demands that current ad-hoc memory management techniques fail to validate. The industry lacks a single, standardized evaluation suite to quantify performance degradation due to context decay, creating a significant bottleneck for reliable local LLM deployment.
What it is
A specialized, rigorous simulation framework designed not just to test memory, but to establish the operational standard for measuring context-aware reasoning integrity across various multi-agent communication patterns and memory compaction strategies.
How it works
- Define standardized, complex agent workflows (e.g., multi-step debugging, complex data synthesis). 2. Feed raw interaction logs through the framework. 3. Systematically inject and test competing context management modules (e.g., graph recall, hierarchical summarization, advanced pruning). 4. Measure and report two primary metrics: operational latency and a quantifiable, standardized 'Reasoning Fidelity Score' against a ground-truth trace.
Differentiation
We are not building another 'tool'; we are building the required evaluation standard. Our output is not just a graph, but a measurable, reproducible benchmark suite. This positions the suite as the necessary dependency—the 'API' for evaluating multi-agent context reliability—making it an infrastructure cornerstone for the next wave of local AI. (Gap: No existing standardized benchmark for context decay in multi-agent systems.)
Implementation sketch
- Develop the core simulation harness (Python/Rust) accepting defined agent workflow scripts.
- Engineer the 'Reasoning Fidelity Score' metric: A weighted combination of semantic overlap and task completion success rate, rigorously defined against curated gold-standard traces.
- Build a comparative dashboard that visualizes performance degradation against industry best practices, aiming to become the default industry reference point.
First step: Draft a detailed technical specification for the initial Proof-of-Concept (PoC): Focus the benchmark on a single, well-defined failure mode, such as 'Context decay during iterative tool-use for financial data extraction' using a small, curated set of 5 gold-standard traces. This minimizes the initial scope and addresses the feasibility concern.
Remaining risks
- The 'Reasoning Fidelity Score' remains too subjective and complex to adopt as a universal standard, leading to fragmentation where different vendors create proprietary, incompatible evaluation metrics. — Pivot the initial focus away from a single, comprehensive 'Score' and instead standardize the input/output contract for the benchmark. Define clear, measurable thresholds for latency and recall on specific, narrow tasks, allowing vendors to plug in their own scoring mechanisms that must adhere to the established input/output structure.
- The 'Standard' becomes a 'Tool' that requires continuous, expensive maintenance (gold-standard curation), leading to project stagnation or abandonment when funding shifts focus. — Structure the business model around 'Benchmark Certification' rather than 'Benchmark Ownership.' Charge a recurring fee for validating compliance against the MACDS standard, incentivizing continuous updates and adoption from the ecosystem.
- The market perceives the suite as purely academic or theoretical, failing to connect the abstract concept of 'context decay' to immediate, tangible ROI for enterprise clients. — Develop a high-fidelity, low-overhead 'Triage Dashboard' that translates benchmark failure metrics directly into estimated operational costs (e.g., 'This decay rate translates to an estimated 15% reduction in successful API calls in a live financial trading scenario').
Watch for: A major industry player (e.g., Google, OpenAI, Microsoft) announcing a native, standardized context management API or benchmarking suite, which would immediately render MACDS obsolete or require a costly, rapid pivot. Kill criterion: Failure to secure commitment from at least two distinct, non-competing industry groups (e.g., one research lab and one infrastructure vendor) to participate in the initial PoC validation phase within the next 6 months.