
Private, Interpretive Personal Finance Intelligence Layer
A secure, privacy-first dashboard that synthesizes complex personal financial data into actionable, at-a-glance insights, solving the complexity gap for modern consumers.
How can I get actionable financial insights from scattered accounts?
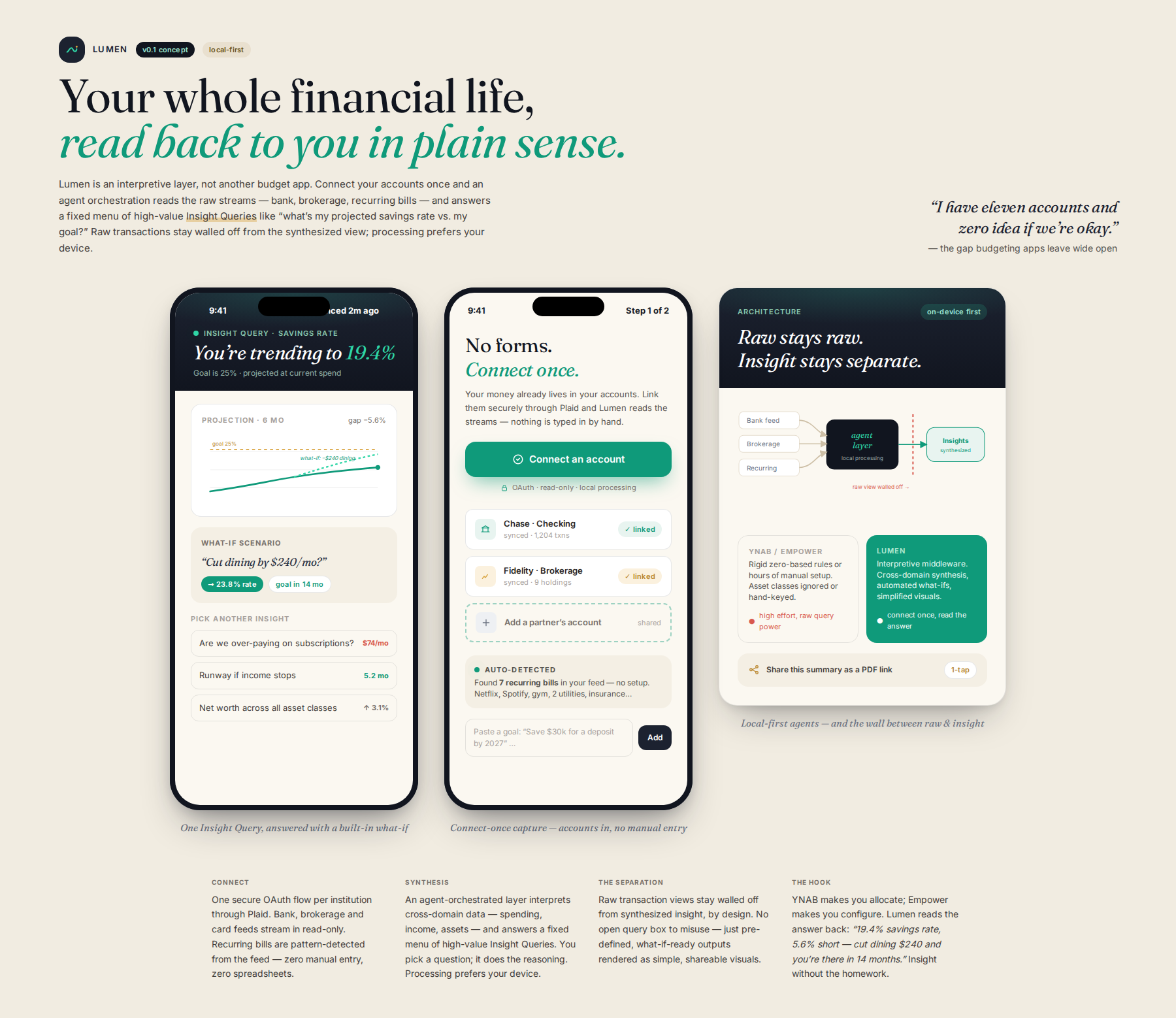
An agent-based layer synthesizes data from multiple personal accounts into actionable at-a-glance insights, surfacing what-if scenarios and spending trends without manual setup. The system connects to your bank and brokerage accounts, automatically detects recurring bills, and generates pre-defined Insight Queries like projected savings rates. It visualizes the gap between raw data and synthesized insights, maintaining clear separation.
Process flow
Who it's for
Individuals managing complex, shared, or varied personal finances (e.g., couples, freelancers) who feel overwhelmed by raw data.
Why they need it
Users need a single, simple interface that synthesizes data across multiple personal accounts and provides clear, actionable insights without forcing them into complex spreadsheets or opaque third-party workflows.
What it is
A modular, agent-based layer that focuses purely on interpreting and visualizing personal financial data streams (bank, brokerage, recurring services) to surface 'what-if' scenarios and spending trends.
How it works
The system utilizes a secure, agent-orchestrated layer (prioritizing local processing) to connect to necessary personal data sources. Instead of exposing raw query power, it surfaces pre-defined, high-value 'Insight Queries' (e.g., 'Projected savings rate based on current spending trends vs. goal X'). The output is a highly visual, simplified report, maintaining a clear separation between raw transaction views and synthesized insights.
Differentiation
Unlike dedicated budgeting apps like YNAB, which are focused on rigid, zero-based allocation and ignore complex asset classes, or comprehensive dashboards like Empower, which require significant manual setup, this system acts as an intelligent middleware. It specifically fills the gap of interpretive synthesis of cross-domain personal financial data (p5, scoped down), providing automated 'what-if' scenario generation and simplified visualization, which existing tools cannot handle without significant user effort.
Implementation sketch
- Prototype the core data ingestion pipeline using a single, read-only, sandbox connection (e.g., a single dummy bank feed) to prove the data structure handling.
- Develop the 'Insight Engine' prototype: Hardcode 3-5 core, high-value synthesis reports (e.g., 'Debt Paydown Trajectory', 'Spending Anomaly Detection') instead of a general query builder.
- Design the UX/UI to prioritize the output (the insight/visualization) over the input (the query/API connection), making the complexity invisible to the user.
First step: Select one small, achievable data source (e.g., a personal credit card statement CSV) and build the first minimum viable 'Insight' visualization based on that single source, proving the interpretation layer works before tackling multi-source connectivity.
Remaining risks
- Data Source Volatility and Maintenance Overhead — Implement a robust, version-controlled adapter layer for every single data source. Prioritize building the initial MVP around sources with stable, well-documented APIs (e.g., major established financial data aggregators) and treat every other source as a 'v2' integration. Budget significant engineering time for ongoing maintenance, recognizing that financial APIs change frequently.
- The 'Insight' Becomes a Black Box (Trust Erosion) — Do not allow the 'Insight Engine' to become a magical black box. For every major synthesized insight, provide a clear, one-click drill-down path showing the exact underlying data points and the specific calculation/logic used to derive the conclusion. Transparency builds trust; opacity breeds suspicion, especially with money.
- Regulatory and Compliance Scope Creep — Treat compliance (GDPR, CCPA, etc.) not as a feature, but as the primary non-negotiable technical constraint from Day 1. Design the architecture with data minimization and anonymization at the core. Engage legal counsel early to define the minimum viable compliance scope for the initial target geography/user base, resisting any urge to build for global compliance immediately.
Watch for: User frustration when the synthesized insight contradicts their gut feeling or known reality. This signals that the 'interpretation layer' is either missing critical context or is making overly aggressive, unvalidated assumptions. Kill criterion: If the initial user testing cohort cannot articulate a clear, emotional pain point that only this synthesized insight solves, or if they are forced to manually correct the synthesized insight more than 20% of the time, the core value proposition of 'automatic interpretation' is fundamentally flawed.
Sources the council used
Real-world evidence that grounded this idea — judge it for yourself.