
Agentic Financial Narrative Builder with Confidence Thresholding
An autonomous AI agent suite for self-employed individuals that transforms disparate, messy financial data into plain-language, actionable narratives, automating routine entries while requiring human verification only for high-risk or novel financial events.
How can I understand my finances without complex bookkeeping software?
An AI agent ingests your bank statements, invoices, and receipts, normalizes the data, and explains what happened in plain language. For routine transactions (subscriptions, bills), it auto-approves the entry; for novel or high-risk items (international transfers, large one-time payments), it generates a narrative requiring your review before posting. This risk-adjusted workflow balances automation with necessary human oversight.
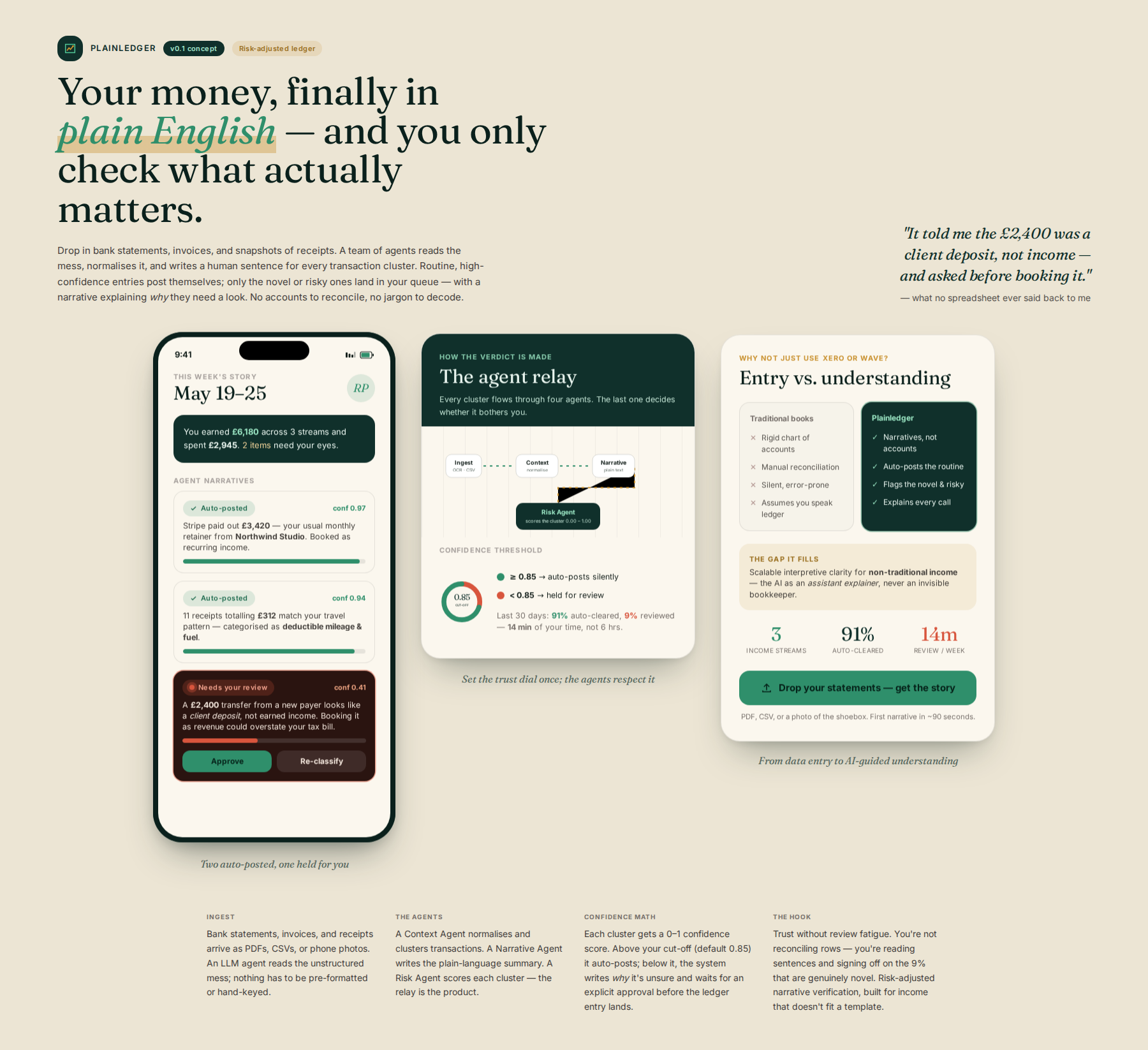
Process flow
Who it's for
Self-employed individuals or those with multiple income streams who are non-accountants.
Why they need it
They struggle not just with bookkeeping complexity, but with understanding the story behind their finances—why a specific transaction occurred, what it implies for taxes, and how it connects to their overall business goals. ('I wish there was something that just handled everything well but... needs to explain why it changed.')
What it is
A specialized, multi-agent financial orchestration platform that acts as a 'Financial Translator,' generating narrative reports and implementing a risk-based approval workflow to ensure trust without creating review fatigue.
How it works
The system uses an LLM agent to ingest unstructured data (bank statements, invoices, receipts via OCR/upload). A 'Context Agent' normalizes the data, which is then fed into a 'Narrative Agent.' This agent generates a plain-language summary. Crucially, a 'Risk Agent' calculates a confidence score for the transaction cluster. If the score is high (routine), the entry is auto-approved; if low (novel/high-risk), the system generates a narrative requiring explicit user review and approval before the final ledger entry.
Differentiation
Unlike comprehensive tools like s1 (Xero) or s2 (Wave), which are built on rigid 'Accounts' and demand manual reconciliation, this platform's core value is Risk-Adjusted Narrative Verification. It shifts the burden from manual data entry to AI-guided understanding. It fills the GAP of Scalable Interpretive Clarity for Non-Traditional Income, ensuring the AI acts as an assistant explainer rather than an invisible, error-prone bookkeeper.
Implementation sketch
- Develop a secure, local-first ingestion module leveraging OCR/API hooks to pull diverse financial data sources.
- Design the 'Context Agent' to normalize data, and pair it with a 'Risk Agent' that assigns a confidence score based on transaction type, vendor history, and deviation from user norms.
- Build the UI around a 'Review & Approve' workflow that dynamically adapts: presenting auto-approval confirmation for low-risk items, and detailed narrative review/approval prompts only for high-risk items.
First step: Prototype the 'Risk Agent' logic: Select 5 common, routine transactions (e.g., Netflix, AWS subscription) and 3 high-risk, novel transactions (e.g., international payment, large one-time vendor). Build a simple scoring mechanism (0-100) to categorize these 8 items into 'Auto-Approve' vs. 'Narrative Review Required' based on predefined heuristics.
Remaining risks
- The 'Risk Agent' scoring mechanism, while mitigating review fatigue, may fail to accurately classify novel but legitimate transactions as low-risk, leading to unnecessary user friction (false positives). Conversely, it might auto-approve a genuinely fraudulent or complex transaction (false negatives), leading to catastrophic financial error and immediate loss of user trust. — Implement a tiered escalation path. If the Risk Agent's confidence score falls into a 'Grey Zone' (e.g., 40-60), the system must trigger a mandatory, simplified user prompt asking, 'Is this transaction related to [Known Project A] or [Known Project B]? Yes/No/Other,' forcing a low-effort decision that guides the model toward the correct classification without demanding a full narrative review.
- The initial data ingestion (OCR/API) remains the single point of failure. If the raw data provided by the user is ambiguous (e.g., a receipt with poor lighting, a bank statement using non-standard abbreviations), the entire chain breaks. The 'Narrative Agent' will then generate a highly confident, but fundamentally incorrect, story based on garbage input. — Mandate a 'Data Integrity Check' layer immediately after ingestion. This layer must flag the source data itself—e.g., 'OCR Confidence: 78% on Vendor Name' or 'API Field Missing: Tax ID'—and force the user to review the source evidence before the Narrative Agent even runs. This shifts the trust requirement back to the raw data, not the narrative.
- The 'local-first' architecture, while a privacy differentiator, introduces massive complexity in cross-device synchronization, backup, and multi-user access management. If the user experiences data loss or inconsistency between their phone and desktop, the perceived value of the 'local-first' advantage evaporates instantly, making the product feel fragile and unreliable. — Scope the initial MVP to a single, controlled environment (e.g., a dedicated mobile app only) and defer cross-device sync. Instead, focus the initial technical pitch on 'Local Processing Guarantee'—the assurance that data never leaves the device unless explicitly authorized for a specific, high-value sync action, making the privacy promise tangible and limited in scope.
Watch for: A user reporting that they have to manually correct the AI's classification more often than they would have with a simple, structured spreadsheet or existing accounting software. This indicates the 'Narrative' is merely adding a layer of cognitive overhead without providing proportional value. Kill criterion: If the system cannot reliably process and generate a narrative for the top 5 most common, routine financial transactions (e.g., recurring SaaS subscriptions, utility bills) with less than 1% manual correction rate across a beta group of 20 users, the core automation promise is broken.
Sources the council used
Real-world evidence that grounded this idea — judge it for yourself.