

Client Challenge
Gaming company launched an AI support assistant that suffered from severe accuracy issues—only 40% correct answers with a 50-60% hallucination rate. Response times averaged 28-42 seconds. The over-quantized model failed to ground responses in actual game documentation, making it unsuitable for production deployment.
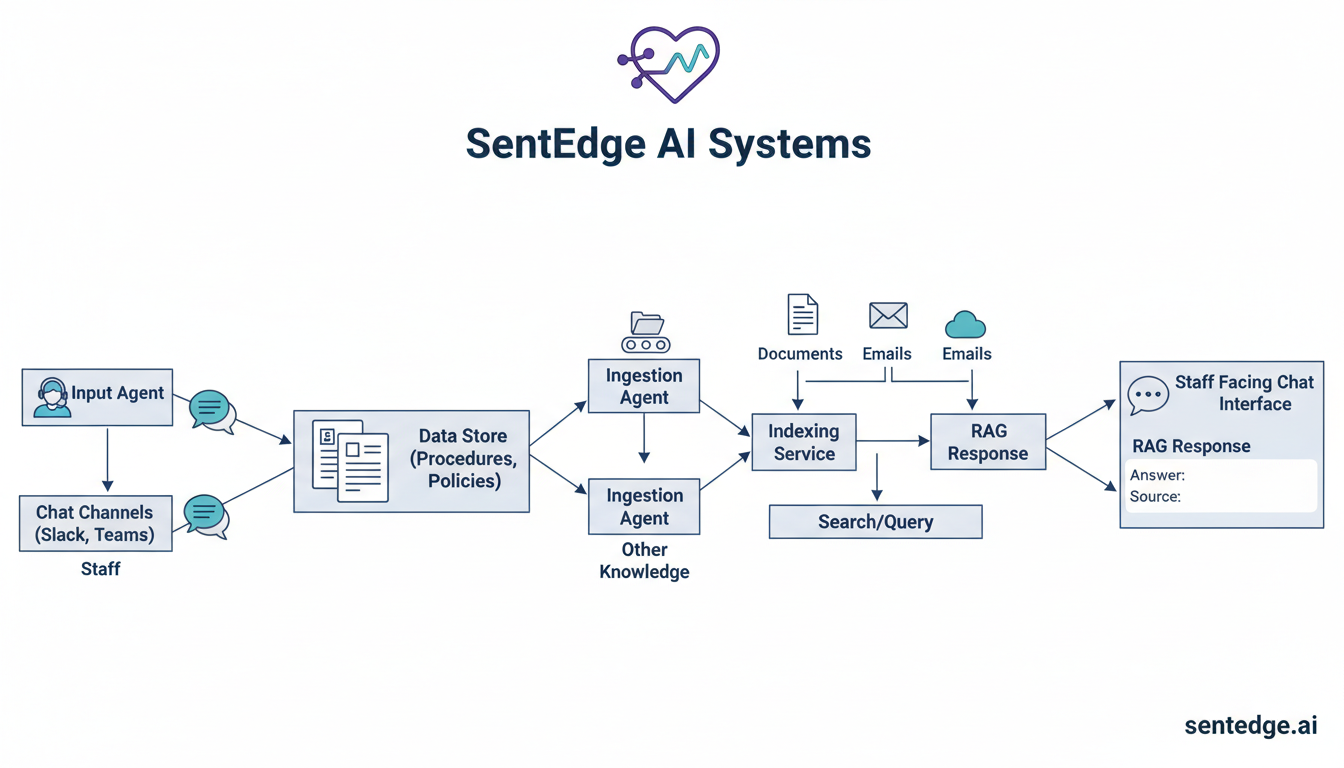
Solution Delivered
- Enterprise RAG pipeline with FAISS semantic search (0.75-0.85 similarity scores)
- Optimized Llama 3.2 3B model with strict context grounding
- Automated validation system ensuring 100% production alignment
- Knowledge base extracted from live UI components for zero-drift accuracy
- 3-phase optimization: prompt engineering → model upgrade → knowledge enhancement
Results
98% Accuracy
90% Fewer Hallucinations
3x Faster (12-18s)
100% Grounding Rate
24/7 Availability
Tech Stack: FAISS + sentence-transformers, Llama 3.2 3B, Flask, CPU-optimized inference (3-4GB RAM)
Improvement: From 40% accuracy → 98% accuracy | 40s response → 12-18s | Hallucinations reduced by 90%